Bloom Filtresi [Veri Yapıları]
14 Haziran 2023 • ☕️ 7 dk okuma • 🏷 bilgisayar, yazılım, algoritma, veri-yapıları
Yazar tarafından şu dillere çevrildi: English
Bloom Filtresi, veri yapıları içinde sıklıkla kullanılan ve özellikle veri arama işlemlerini hızlandırmak için kullanılan oluşturulabilir bir olasılık tabanlı veri yapısıdır. Bu veri yapısı, elemanların varlık durumunu (var olma veya yok olma) hızlı bir şekilde ve düşük bellek kullanımı ile kontrol etmek için kullanılır.
Bloom Filtresi, 1970 yılında Burton Howard Bloom tarafından ortaya atılmıştır ve özellikle büyük veri kümeleri üzerinde etkili bir şekilde çalışır. Bloom Filtresi, yanıtın “kesin olmaması” durumunda kullanılır, yani belirli bir elemanın kümede kesinlikle bulunduğunu veya bulunmadığını belirtmek yerine, olasılıkla bulunduğunu ifade eder. Bu nedenle, Bloom Filtresi hızlı ve hafif olmasının yanı sıra, yanıtın olasılığını kabul edilebilir bir hata marjı ile sağlayabilir.
Bloom Filter, probabilistik (olasılıksal) bir veri yapısıdır. Bir öğenin bir kümede olup olmadığını kontrol etmek için kullanılır. Bu, diğer veri yapıları kullanılarak da elde edilebilir. Ancak, Bloom filtresi bunu verimli bir şekilde yapar.
Algoritma
Boş bir Bloom Filtresi, tümü 0 olarak ayarlanmış m bitlik bir bit dizisidir. Ayrıca, her biri bir m dizisi konumuna bazı set elemanını eşleyen veya karmaşıklaştıran k farklı hash fonksiyonu tanımlanmalıdır. Bu, uniform bir rastgele dağılım oluşturur. Genellikle k, m’den çok daha küçük bir sabittir ve eklenen elemanların sayısına orantılıdır; k’nın ve m’nin orantılı sabiti, filtrenin amaçlanan yanlış pozitif oranına göre belirlenir.
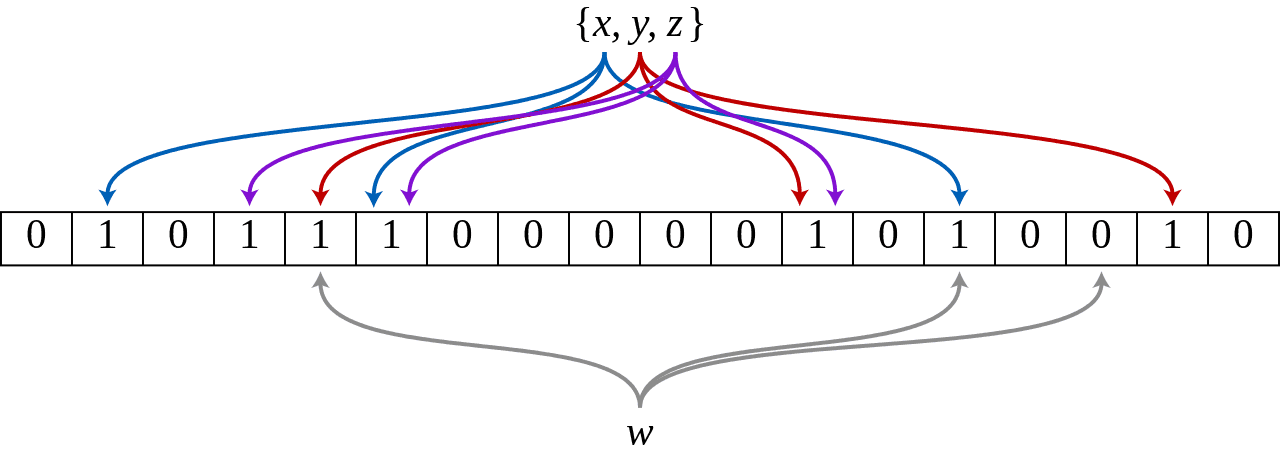
Aşağıda {x, y, z} kümesini temsil eden bir Bloom Filtresi örneğini görebiliriz. Renkli oklar, her set elemanının bit dizisinde eşleştirildiği konumları gösterir. W elemanı {x, y, z} kümesinde bulunmamaktadır, çünkü 0 içeren bir bit-dizi konumuna karmaşıklaştırılmıştır. Bu şekil için m = 18 ve k = 3’tür.
Bloom Filtresi, bir dizi k-bit uzunluğunda bir bit dizisi ve birkaç hash fonksiyonundan oluşur. İşleyişi şu şekildedir:
- Önceden belirlenmiş k adet boş bit içeren bir dizi oluşturulur.
- Eklenecek bir eleman geldiğinde, bu eleman için k adet farklı hash fonksiyonu kullanılır. Her hash fonksiyonu elemanın bir pozisyonunu döndürür.
- Elde edilen bu pozisyonlar, bit dizisindeki ilgili pozisyonlara işaretlenir (1 değeri verilir).
- Arama yapmak istediğimizde, aynı hash fonksiyonları kullanarak elemanın k pozisyonunu elde ederiz. Eğer bu pozisyonlardaki bitlerin tamamı 1 ise, elemanın muhtemelen veri kümesinde olduğu sonucuna varırız. Ancak, eğer en az bir pozisyonda 0 varsa, elemanın veri kümesinde kesinlikle olmadığı sonucuna varırız.
Bloom Filtresi Operasyonları
1. Ekleme (Insertion)
Bu işlem veri kümesine yeni bir elemanın eklenmesini ifade eder. Bu işlem, veri kümesine eleman eklemek için Bloom Filtresi’ni güncellemenin yollarından biridir.
Ekleme işlemi, şu adımlarla gerçekleştirilir:
- Veri kümesine eklemek istediğimiz bir eleman (örneğin, eleman X) belirlenir.
- Eleman X için Bloom Filtresi’nin içinde bulunan k farklı hash fonksiyonu kullanılır.
- Her bir hash fonksiyonu eleman X’in m bitlik Bloom Filtresi içindeki k farklı pozisyonlarını belirler.
- Belirlenen bu pozisyonlardaki bitler 1 olarak işaretlenir (set edilir).
- Bloom Filtresi, eleman X’i içeren veri kümesini temsil etmek üzere güncellenmiş olur.
Bu adımlar, elemanın olası pozisyonlarına işaretlenmesi sayesinde Bloom Filtresi’nin belirli bir elemanın varlığını belirleme yeteneğini sağlar. Ancak unutulmamalıdır ki Bloom Filtresi, eleman ekledikçe yanlış pozitif olasılığının artacağı bir özelliğe sahiptir. Bu nedenle, yanıtların kesin olmaması ve yanlış pozitif sonuçlarının olasılığı kabul edilebilir olduğu durumlarda kullanılması önemlidir.
2. Arama (Search)
Arama işlemi, bir elemanın Bloom Filtresi’nde var olup olmadığını sorgulamak için kullanılır. Bloom Filtresi, bir elemanın var olma ihtimalini yüksek hızda belirlemek için tasarlanmıştır, ancak yanıtların kesin olmaması kabul edilebilir. Yani, bir elemanın filtrenin içinde kesinlikle bulunup bulunmadığını söylemek yerine, muhtemelen var olduğunu veya kesinlikle olmadığını ifade eder.
Arama işlemi, şu adımlarla gerçekleştirilir:
- Aramak istediğimiz elemanın (örneğin, eleman Y) varlığını kontrol etmek için Bloom Filtresi’nin içinde bulunan k farklı hash fonksiyonu kullanılır.
- Her bir hash fonksiyonu, eleman Y’in Bloom Filtresi içindeki k farklı pozisyonlarını belirler.
- Belirlenen bu pozisyonlardaki bitlerin değerleri kontrol edilir. Eğer tüm pozisyonlardaki bitler 1 ise, eleman Y’ın muhtemelen filtrenin içinde olduğu sonucuna varılır. Ancak, en az bir pozisyondaki bit 0 ise, eleman Y’ın kesinlikle filtrenin içinde olmadığı sonucuna varılır.
Sorgulama işlemi, hızlı ve düşük bellek kullanımı sayesinde büyük veri kümeleri üzerinde etkili bir şekilde çalışır. Ancak, yanıtların kesin olmaması ve yanlış pozitif sonuçların (false positive) olasılığı göz önünde bulundurulmalıdır.
False Positives
False Positive (Yanlış Pozitif) kavramı, Bloom Filtresi’nde bir elemanın filtrenin içinde olmadığı halde, sorgulama işlemi sonucunda var olduğu yanıtının verilmesini ifade eder. Yani, aslında veri kümesinde bulunmayan bir elemanın, Bloom Filtresi sorgusunda olumlu sonuç vermesidir.
Bu yanıltıcı pozitif sonuçlar, özellikle Bloom Filtresi’nin boyutu (m), hash fonksiyonu sayısı (k) ve veri kümesi boyutu arasındaki ilişki nedeniyle oluşur. Filtrenin boyutu (m) ve kullanılan hash fonksiyonları sayısı (k), Bloom Filtresi’nin yanıltıcı pozitif olasılığını etkiler. Yanıltıcı pozitif oranı, filtrenin dolum oranı ve hash fonksiyonlarının dağılımıyla ilişkilidir.
Yanıltıcı pozitif sonuçlar, uygulamanın türüne ve hassasiyet gereksinimlerine bağlı olarak kabul edilebilir olabilir veya olmayabilir. Örneğin, bir veri kümesinde bulunmayan bir elemanın yanlışlıkla filtrede var olduğu belirlenirse, bu durumun uygulama için ciddi sonuçları olabilir. Bu nedenle, Bloom Filtresi kullanılırken yanıltıcı pozitif olasılığının tolerans düzeyi ve uygulama senaryosuna uygunluğu dikkate alınmalıdır.
Yanıltıcı pozitif olasılığını düşürmek için, daha büyük bir Bloom Filtresi kullanmak, daha fazla hash fonksiyonu kullanmak veya veri kümesinin boyutunu optimize etmek gibi yöntemler uygulanabilir. Ancak, bu tür düzeltmeler genellikle Bloom Filtresi’nin bellek ve işlemci kullanımını artırabilir. Dolayısıyla, yanıltıcı pozitif olasılığını düşürmek ve yanıltıcı pozitiflerin kabul edilemez olduğu durumlarda, diğer veri yapıları veya filtreleme yöntemleri tercih edilmelidir.
GoLang’de Bloom Filtresi uygulaması:
package main
import (
"fmt"
"hash/fnv"
)
type BloomFilter struct {
bitArray []bool
hashFunc []func(string) uint32
}
func NewBloomFilter(size int, numHashFunc int) *BloomFilter {
bitArray := make([]bool, size)
hashFunc := make([]func(string) uint32, numHashFunc)
for i := 0; i < numHashFunc; i++ {
hashFunc[i] = createHashFunc(i, size)
}
return &BloomFilter{
bitArray: bitArray,
hashFunc: hashFunc,
}
}
func (bf *BloomFilter) Add(item string) {
for _, hf := range bf.hashFunc {
index := hf(item) % uint32(len(bf.bitArray))
bf.bitArray[index] = true
}
}
func (bf *BloomFilter) Contains(item string) bool {
for _, hf := range bf.hashFunc {
index := hf(item) % uint32(len(bf.bitArray))
if !bf.bitArray[index] {
return false
}
}
return true
}
func createHashFunc(seed int, size int) func(string) uint32 {
return func(data string) uint32 {
hash := fnv.New32a()
hash.Write([]byte(data))
return uint32(seed) + hash.Sum32()%uint32(size)
}
}
func main() {
filter := NewBloomFilter(20, 3)
// Elemanları filtreye ekleme
filter.Add("apple")
filter.Add("banana")
filter.Add("orange")
// Elemanların filtreye ait olup olmadığını sorgulama
fmt.Println(filter.Contains("apple")) // true
fmt.Println(filter.Contains("banana")) // true
fmt.Println(filter.Contains("orange")) // true
fmt.Println(filter.Contains("grape")) // false (yanlış pozitif)
fmt.Println(filter.Contains("cherry")) // false (yanlış pozitif)
}Bu kod örneğinde, basit bir Bloom Filtresi implementasyonu yapılmıştır. NewBloomFilter fonksiyonu ile Bloom Filtresi oluşturulurken, filtre boyutu (size) ve kullanılacak hash fonksiyonu sayısı (numHashFunc) belirtilmektedir. Add fonksiyonu ile elemanlar filtre içine eklenir ve Contains fonksiyonu ile elemanlar filtrenin içinde olup olmadığı sorgulanır. createHashFunc fonksiyonu, hash fonksiyonlarını oluşturmak için kullanılır ve basit bir FNV (Fowler-Noll-Vo) hash algoritması kullanılmıştır.
Program çalıştırıldığında çıktısı aşağıdaki gibi olacaktır.
true
true
true
false
trueProgramın çalışır haline şuradan erişilebilir.
Kullanım Alanları
Bloom Filtresi, belirli özellikleri nedeniyle çeşitli kullanım alanlarında tercih edilen bir veri yapısıdır. Aşağıda, Bloom Filtresi’nin yaygın olarak kullanıldığı bazı alanlar bulunmaktadır:
- Veri Tabanı ve Önbellek Yönetimi: Büyük veri tabanları üzerinde hızlı sorgulamalar yapmak için kullanılır. Özellikle veri tabanında bulunan veya henüz oluşturulmamış olası sorgulamaları hızlandırmak için Bloom Filtresi, veritabanının daha az yüklenmesini sağlar. Aynı şekilde, önbellek yönetiminde de sık kullanılır.
- Web Tarayıcılarında URL Geçmişi: Web tarayıcılarında, ziyaret edilen URL’leri veya web sayfalarını hafızada tutmak için Bloom Filtresi kullanılabilir. Bu, tarayıcıların ziyaret edilen sayfaları daha hızlı bir şekilde sorgulayabilmesine yardımcı olur.
- Dağıtık Sistemler: Dağıtık sistemlerde, verilerin varlığını hızlı bir şekilde sorgulamak için kullanılır. Örneğin, dağıtık dosya sistemlerinde veya dağıtık anahtar-değer depolama sistemlerinde anahtarların varlığını kontrol etmek için Bloom Filtresi kullanılabilir.
- Spam Filtreleme: E-posta veya mesaj uygulamalarında, spam e-postalarını veya spam mesajları hızlı bir şekilde filtrelemek için Bloom Filtresi kullanılabilir. Böylece, spam filtreleme işlemleri daha hızlı gerçekleştirilebilir.
- Grafik ve Ağ Algoritmaları: Grafiklerde ve ağ algoritmalarında kullanılan belirli veri yapılarını hızlandırmak için Bloom Filtresi tercih edilebilir. Örneğin, grafik veri yapısındaki düğümlerin varlığını kontrol etmek veya ağdaki bağlantıları takip etmek için kullanılabilir.
- Hafıza Verimliliği Gerektiren Uygulamalar: Bloom Filtresi, diğer veri yapılarına göre daha az bellek tüketir. Bu nedenle, hafıza verimliliğinin önemli olduğu uygulamalarda tercih edilir.
Kaynaklar
- https://en.wikipedia.org/wiki/Bloom_filter
- https://www.baeldung.com/cs/bloom-filter
- https://systemdesign.one/bloom-filters-explained/
- https://www.enjoyalgorithms.com/blog/bloom-filter
- https://brilliant.org/wiki/bloom-filter/#:~:text=A%20bloom%20filter%20is%20a,is%20added%20to%20the%20set.