Concurrency in Go: Channels, Goroutines, and Synchronization Mechanisms
November 23, 2024 • ☕️☕️ 11 min read • 🏷 computer, software, algorithm
Translated by author into: English
Go (Golang) is a modern programming language designed by Google in 2007 and published as open source in 2009, focusing on developing high-performance and scalable software. Thanks to its simple and understandable syntax, it can be easily learned by both experienced and novice developers. At the same time, since it is a lightweight and fast-compiling language, C-like performance can be achieved.
One of the most powerful features of Go is its concurrency support embedded at the language level. The concept of concurrency is critical for providing high efficiency and scalability in modern applications. Goroutines, the basic building block that enables the use of concurrency in Go, offer a much lighter and easier-to-manage approach than traditional threads. In addition, mechanisms such as channels are provided to simplify the communication and synchronization of concurrently running parts. In this way, a reliable and clean design based on the “sharing by communicating” approach can be implemented instead of shared data management.
1. What is Concurrency? Differences from Parallelism
First of all, it is useful to distinguish two terms that are often confused: concurrency and parallelism.
- Concurrency: The ability of a program to progress more than one job in the same time interval (interleaving). Jobs are run in pieces in short periods of time one after the other, giving the user the impression that more than one job is running at the same time. The operating system kernel or the language runtime decides when which job will be run (schedule).
- Parallelism: The physical execution of more than one job at the same time. For example, in a multi-core CPU, multiple cores can work on different processes at the same time.
Go makes concurrency very easy to use, but this concurrency feature does not mean that it will always run “in parallel” on the same machine. The Go runtime determines which goroutine will be run on which core or when. When configured correctly and running on a multi-core processor, your Go code can provide both concurrency and parallelism.
2. What is a Goroutine?
The basic building block of concurrency in Go is goroutines. A goroutine can be thought of as a lightweight thread running inside the Go runtime. Starting a goroutine in Go is very simple. You can run any function in a separate goroutine by prefixing it with the go keyword.
package main
import (
"fmt"
"time"
)
func helloWorld() {
fmt.Println("Hello World!")
}
func main() {
// Run the helloWorld function in a new goroutine
go helloWorld()
// Let's wait a bit in the main goroutine so that the other goroutine can run as well.
time.Sleep(time.Second)
fmt.Println("The main goroutine has ended.")
}In the example above, when we call the helloWorld() function with the go helloWorld() statement, this function starts working independently of the main goroutine. As soon as the main goroutine ends, the program will terminate, so there is no way for the other goroutine to work. Therefore, we add a small time.Sleep() and wait for the other goroutine to produce a result.
Important Note: In real projects, instead of using time.Sleep() for waiting, it is usually a more correct approach to use sync.WaitGroup or similar structures, which are one of the synchronization mechanisms.
3. Channels
Channels are data structures in Go that allow data to be transferred between goroutines in a secure and synchronous manner. The biggest advantage of channels is that instead of using shared variables to manage locks, they allow data to be transferred between goroutines. This approach is a good example of the “communicating by sharing vs. sharing by communicating” philosophy.
3.1 Creating a Channel and Sending/Receiving Data
A channel is created as follows:
ch := make(chan int) // Creates a channel of type int (unbuffered channel)Data sending and receiving is done with the <- operator:
- Sending:
ch <- x - Receiving:
y := <-ch
A sample usage:
package main
import (
"fmt"
)
func main() {
ch := make(chan string)
go func() {
// Sending data
ch <- "Data from Goroutine"
}()
// Receiving data
data := <-ch
fmt.Println(data)
}In the example above, we are running an anonymous function as a goroutine, and this function sends a string to the ch channel. The main goroutine reads this string with the expression data := <-ch.
3.2 Buffered Channels
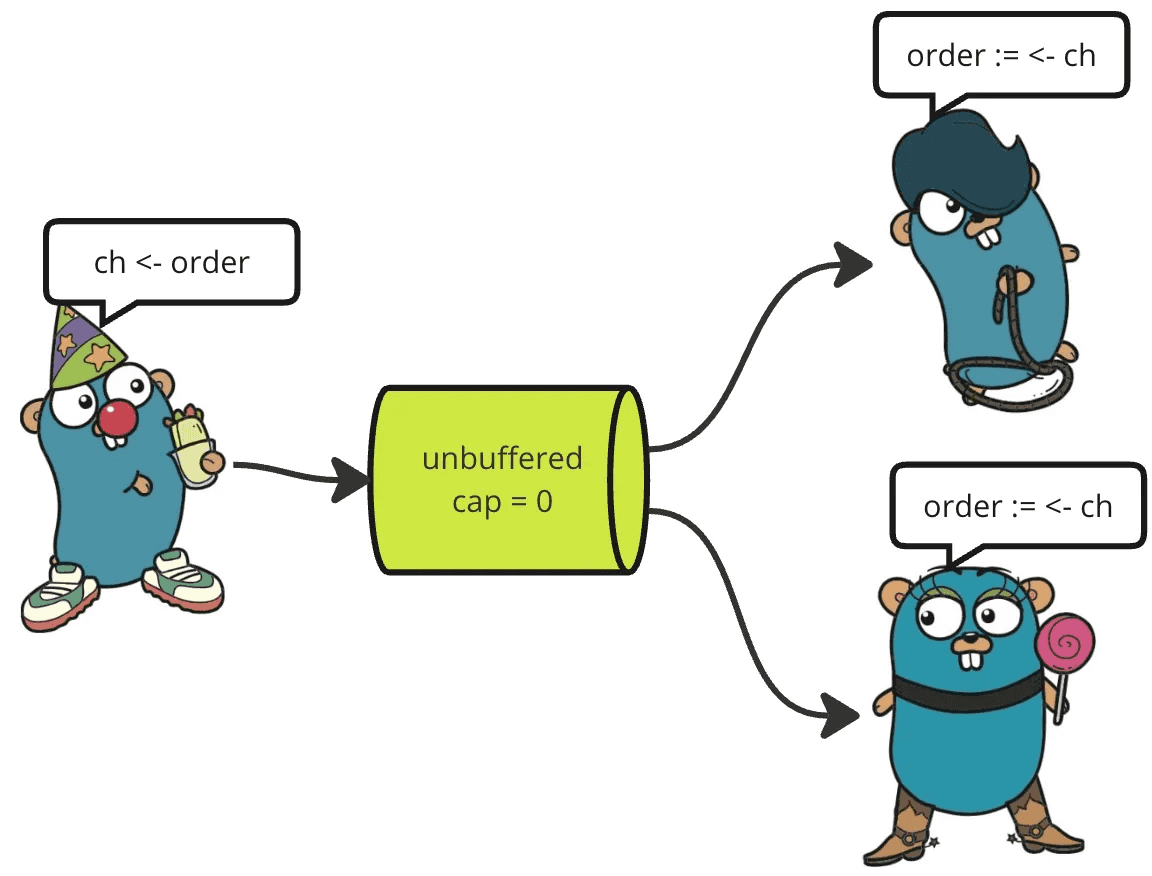
The standard channels are called “unbuffered” and expect the sender and receiver to perform the operation at the same time. In other words, each transmission of the channel is blocked until it is read by a receiver.
If you create a channel with a certain capacity, it is a “buffered channel”. This channel can hold a certain number of messages without a reader.
ch := make(chan int, 5) // A buffered channel with a capacity of 5In this case, you can send a maximum of 5 int values to the ch channel, even if the receiver is not expecting it. However, the 6th transmission will be blocked until a value is received, since the capacity is full.
3.3 Closing the Channel (close)
You can close the channel with the close(ch) function. If data is tried to be sent to a closed channel again, a “panic” occurs. You can continue to read data from the closed channel, but when there is no more data to read, a “zero value” (0 for int, "" for string, etc.) will be returned.
package main
import (
"fmt"
)
func main() {
ch := make(chan int, 3)
ch <- 10
ch <- 20
close(ch)
// Since the channel is closed, we can continue to read data,
// but as soon as we try to write, a panic occurs.
for val := range ch {
fmt.Println(val)
}
}In the example above, the range statement reads all available values in the closed channel, terminating the loop when there is no new data.
4. Synchronization Mechanisms
When dealing with concurrency, multiple goroutines may need to access the same resource, update or read shared data. In these cases, we need synchronization methods to maintain data consistency.
4.1 sync.WaitGroup
The most basic structure used to wait for multiple goroutines to complete is sync.WaitGroup. In the example below, we run three different functions in three separate goroutines and wait for all of them to finish using WaitGroup:
package main
import (
"fmt"
"sync"
"time"
)
func doWork(num int, wg *sync.WaitGroup) {
defer wg.Done() // When the function finishes, the counter is decremented by calling Done().
fmt.Printf("Goroutine %d started\n", num)
time.Sleep(time.Millisecond * 500) // For example, let's wait 500 ms
fmt.Printf("Goroutine %d finished\n", num)
}
func main() {
var wg sync.WaitGroup
toplamGoroutine := 3
wg.Add(toplamGoroutine) // We are waiting for 3 goroutines
for i := 1; i <= toplamGoroutine; i++ {
go doWork(i, &wg)
}
// Waits until all goroutines are finished
wg.Wait()
fmt.Println("All goroutines completed")
}Above:
- We specify the number of goroutines to wait for with
wg.Add(n). - We decrement the WaitGroup counter by 1 when the goroutine is finished by calling
defer wg.Done()inside each goroutine. - The
wg.Wait()statement waits for all goroutines (added with add) to complete.
4.2 sync.Mutex and sync.RWMutex
sync.Mutex (mutual exclusion lock) is used to ensure data consistency when shared data is accessed simultaneously. A “mutex” allows only one goroutine to access the shared resource at a time.
package main
import (
"fmt"
"sync"
)
type SafeCounter struct {
mu sync.Mutex
count int
}
func (sc *SafeCounter) Increment() {
sc.mu.Lock()
defer sc.mu.Unlock()
sc.count++
}
func (sc *SafeCounter) Value() int {
sc.mu.Lock()
defer sc.mu.Unlock()
return sc.count
}
func main() {
var wg sync.WaitGroup
sc := SafeCounter{}
goroutineCount := 5
wg.Add(goroutineCount)
for i := 0; i < goroutineCount; i++ {
go func() {
defer wg.Done()
for j := 0; j < 1000; j++ {
sc.Increment()
}
}()
}
wg.Wait()
fmt.Println("Total:", sc.Value())
}- In the
Increment()andValue()methods, we ensure that only one goroutine can access the data at a time withLock()andUnlock(). Thus, data consistency is maintained. RWMutexis a read-write lock that allows multiple reader goroutines at the same time, but allows only the writer when a writer enters. Thus, it generally provides performance gains in cases where reading operations are mostly performed.
4.3 sync.Once
Sometimes you may want a certain function or operation to run only once throughout the program. For this case, the sync.Once structure is used. It is especially useful when operations such as configuration and cache initialization are to be done only once.
package main
import (
"fmt"
"sync"
)
var once sync.Once
func initConfig() {
fmt.Println("The configuration is started.")
}
func main() {
var wg sync.WaitGroup
wg.Add(3)
for i := 0; i < 3; i++ {
go func(id int) {
defer wg.Done()
once.Do(initConfig)
fmt.Printf("Goroutine %d is running.\n", id)
}(i)
}
wg.Wait()
}In this example, the initConfig() function will only be executed once, no matter how many goroutines it calls.
5. Things to Consider in Concurrency
- Data Race: If more than one goroutine tries to read and write the same variable at the same time, a data race occurs. In this case, you may get unexpected results. You can test a data race in your Go program with the
go run -race main.gocommand. - Forgetting Locks: If you forget to unlock a
Mutexwhile using it, other goroutines may wait forever. Therefore, approaches such asdefer mu.Unlock()are recommended. - Scalability: Although goroutines are very lightweight, using too many goroutines can exhaust system resources. Although it is theoretically possible to start millions of goroutines, there are memory and processor limits that need to be taken into account in practice.
- Unclosed Channels: Especially in long-lived services, channel usage should be managed carefully. If unneeded channels are not closed at the right time, waiting goroutines may block or a “goroutine leak” may occur.
- Timing and Race Conditions: Concurrency increases complexity. It is difficult to predict exactly in which order the code will run. Therefore, testing strategies, logging and memory monitoring (profiling) are important.
6. Example: Workers and Pipe-Based Queue
Below is a sample code that starts 3 “worker” goroutines to process 10 jobs, reads the jobs from a pipe, and processes them:
package main
import (
"fmt"
"sync"
"time"
)
// Task represents an item or job to be processed
type Task struct {
ID int
}
// worker function processes tasks from the channel
func worker(id int, taskChan <-chan Task, wg *sync.WaitGroup) {
defer wg.Done()
for task := range taskChan {
fmt.Printf("Worker %d is processing task %d...\n", id, task.ID)
// Simulate some work
time.Sleep(time.Millisecond * 100)
fmt.Printf("Worker %d has completed task %d.\n", id, task.ID)
}
}
func main() {
taskCount := 10
workerCount := 3
// Create a channel to send tasks
taskChan := make(chan Task, taskCount)
// A WaitGroup will ensure that all tasks and workers finish
var wg sync.WaitGroup
// Start 3 workers
for i := 1; i <= workerCount; i++ {
wg.Add(1)
go worker(i, taskChan, &wg)
}
// Send 10 tasks to the channel
for i := 1; i <= taskCount; i++ {
taskChan <- Task{ID: i}
}
// Close the channel once all tasks have been sent
close(taskChan)
// Wait for all workers to finish
wg.Wait()
fmt.Println("All tasks have been processed, the program is now terminating.")
}- The
workerfunction processes the tasks (with range) received from thetaskChan. When the channel is closed, the range loop ends and the function exits. In the main function,wg.Add(1)is used to start 3 workers. Each worker callswg.Done()when it is completed. When the tasks are completed, the program ends.
When the program is run, its output will be as follows.
Worker 3 is processing task 1...
Worker 1 is processing task 2...
Worker 2 is processing task 3...
Worker 2 has completed task 3.
Worker 2 is processing task 4...
Worker 3 has completed task 1.
Worker 3 is processing task 5...
Worker 1 has completed task 2.
Worker 1 is processing task 6...
Worker 1 has completed task 6.
Worker 1 is processing task 7...
Worker 2 has completed task 4.
Worker 2 is processing task 8...
Worker 3 has completed task 5.
Worker 3 is processing task 9...
Worker 2 has completed task 8.
Worker 2 is processing task 10...
Worker 3 has completed task 9.
Worker 1 has completed task 7.
Worker 2 has completed task 10.
All tasks have been processed, the program is now terminating.The working version of the program is available here.
This approach is known as a “worker pool” and is generally ideal for sharing large amounts of work across a number of concurrent processors, streamlining resource usage and providing performance and scalability.
Go is a language focused on simplicity and efficiency, and perfectly supports concurrency at the language level.
- Goroutines are much lighter and easier to manage structures than system threads.
- Channels adopt the messaging paradigm instead of sharing data and make communication between goroutines secure.
- sync package (structures such as WaitGroup, Mutex, RWMutex, Once) includes synchronization mechanisms commonly used in concurrency scenarios.
By using these tools correctly and consciously, you can develop high-performance and scalable Go applications. However, concurrency also brings complexity. You should carefully design, test and use the necessary profiling tools to avoid problems such as data race conditions and deadlocks.
Remember: Concurrency is a very powerful tool when used correctly; when used incorrectly, it can turn into a nightmare that is difficult to track and fix. Go’s simple concurrency model and rich standard library provide great convenience in this regard.
Resources
- https://go.dev/
- https://medium.com/@gopinathr143/go-concurrency-patterns-a-deep-dive-a2750f98a102
- https://blog.stackademic.com/go-concurrency-visually-explained-channel-c6f88070aafa