Raft Algoritması: Dağıtık Sistemlerde Basit ve Güvenilir Konsensus
2 Mayıs 2025 • ☕️☕️☕️☕️ 18 dk okuma • 🏷 bilgisayar, yazılım, algoritma
Yazar tarafından şu dillere çevrildi: English
Dağıtık sistemler, modern yazılım mimarisinin temelini oluşturur. Ancak birden fazla sunucunun aynı anda çalışması, veri tutarlılığını ve sistemin hata toleransını sağlamak gibi karmaşık zorlukları da beraberinde getirir. Bu zorlukların merkezinde “konsensus” problemi yatar: bir grup sunucunun, ağ kesintileri veya sunucu arızaları gibi aksaklıklara rağmen tek bir değer veya eylem üzerinde anlaşmaya varması. Bu makale, dağıtık sistemlerde konsensus sağlamak için tasarlanmış, basitliği ve güvenilirliğiyle öne çıkan Raft algoritmasını derinlemesine inceleyecektir.
Paxos Neden Karmaşıktı?
Raft’tan önce, dağıtık konsensus için fiili standart Paxos algoritmasıydı. Leslie Lamport tarafından 1970’lerde tanımlanan Paxos, teorik olarak sağlam ve hataya dayanıklı bir çözüm sunuyordu. Ancak, Paxos’un en büyük eleştirisi, anlaşılmasının ve doğru bir şekilde uygulanmasının son derece zor olmasıydı. Karmaşıklığı, geliştiricilerin onu benimsemesini ve genişletmesini engelliyordu, bu da alternatif arayışlarını tetikledi.
Raft’ın Temel Prensipleri ve Tasarım Felsefesi
Diego Ongaro ve John Ousterhout tarafından 2013 yılında tanıtılan Raft, Paxos’a daha anlaşılır bir alternatif olarak tasarlandı. Raft’ın birincil hedefi, mantığı ayırarak ve sunucuların tutarsız olabileceği yolları azaltarak anlaşılabilirliği artırmaktı.
Raft, “çoğaltılmış durum makineleri” (replicated state machines) kavramı üzerine kuruludur. Temel fikir, ayrı sunucuların belirli bir “şey” üzerinde, özellikle de bir log üzerinde anlaşmasını sağlamaktır. Bu log, sistemin durumunu değiştiren komutların bir kaydıdır. Tüm sunucular aynı komut dizisini aynı sırayla uyguladığında, hepsi aynı duruma ulaşır ve sistem tutarlı kalır.
Raft, konsensus problemini üç bağımsız alt probleme ayırarak bu anlaşılabilirliği sağlar:
- Lider Seçimi (Leader Election): Mevcut liderin başarısız olması durumunda yeni bir liderin nasıl seçileceği.
- Log Çoğaltma (Log Replication): Liderin istemci isteklerini nasıl kabul edeceği ve bunları diğer sunuculara nasıl çoğaltacağı.
- Güvenlik (Safety): Sistemin hiçbir zaman tutarsız bir duruma düşmemesini sağlayan mekanizmalar.
Raft, bu alt problemlerin her birini açık ve ayrı kurallarla ele alarak, Paxos’un aksine “lider tabanlı” bir yaklaşım benimser. Kümede yalnızca bir lider seçilir ve bu lider, log çoğaltmayı yönetmekten tamamen sorumludur.
Raft’ın Bileşenleri ve Durumları
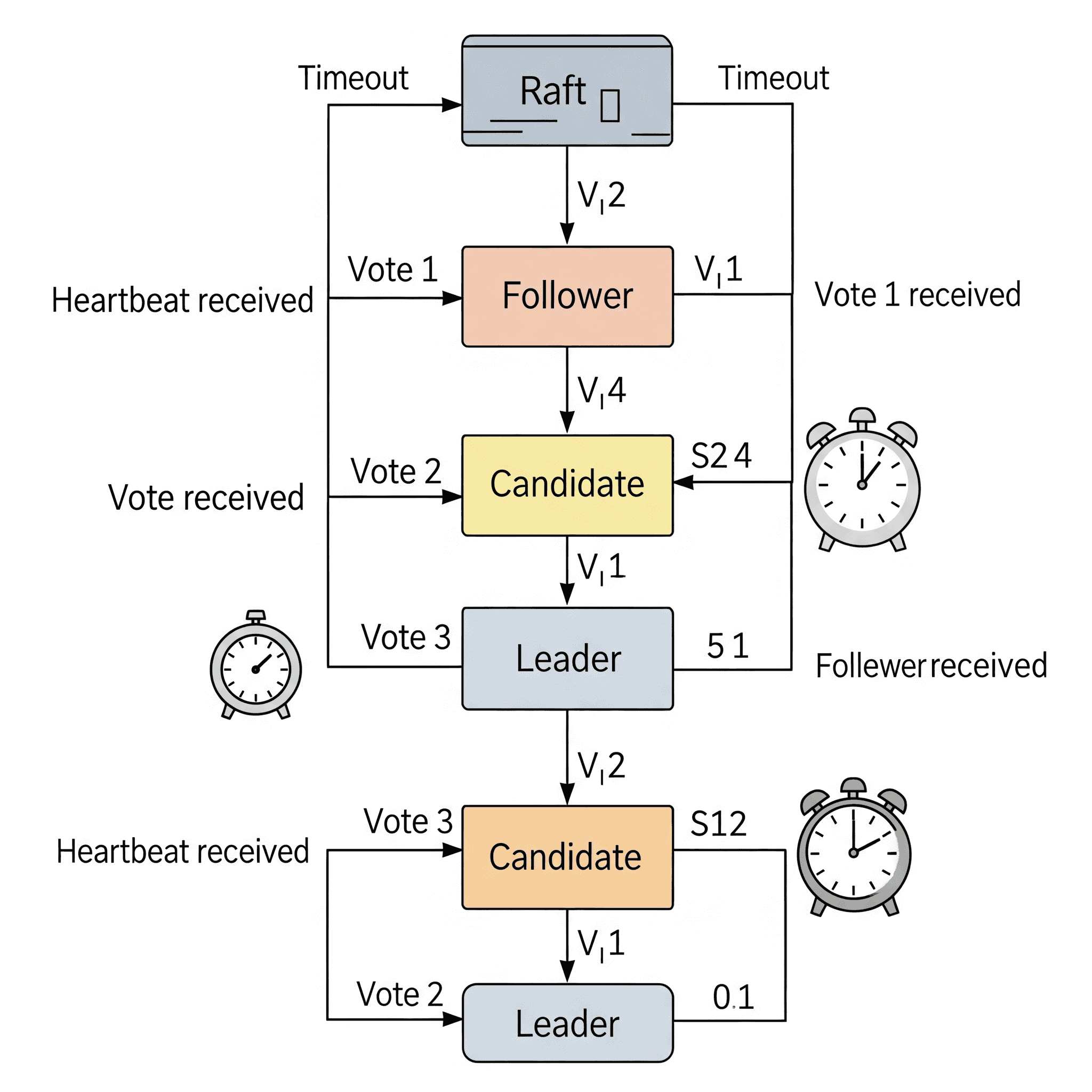
Raft kümesindeki her sunucu, herhangi bir zamanda üç durumdan birinde bulunur:
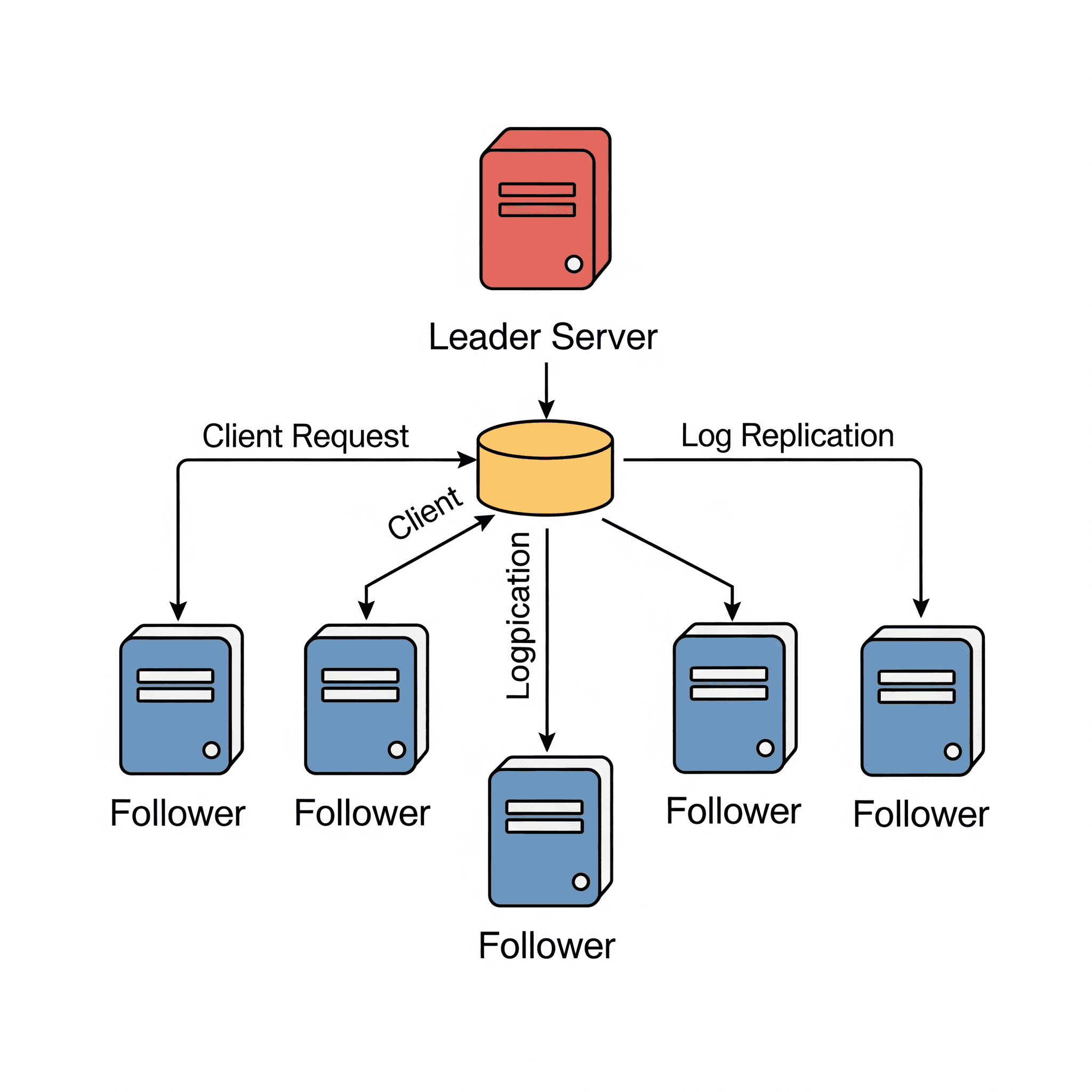
- Lider (Leader): İstemci isteklerini kabul eden, log girişlerini yöneten ve bunları takipçilere çoğaltan merkezi otoritedir. Normal çalışmada kümede tam olarak bir lider bulunur.
- Takipçi (Follower): Liderin log girişlerini çoğaltan ve liderden gelen isteklere yanıt veren pasif düğümlerdir.
- Aday (Candidate): Liderin belirli bir süre içinde yanıt vermemesi durumunda liderlik için aday olan düğümlerdir.
Terimler (Terms)
Raft, zamanı “terimler” adı verilen ardışık tam sayılarla numaralandırılmış mantıksal zaman aralıklarına böler. Her terim bir seçimle başlar. Bir lider seçildiğinde, terim sona erene veya lider başarısız olana kadar sorumlu kalır. Terim numaraları, düğümlerin güncel bilgileri senkronize etmesine, çakışmaları çözmesine ve seçimleri koordine etmesine yardımcı olur.
RPC’ler (Remote Procedure Calls)
Raft, iletişim için iki ana Uzak Prosedür Çağrısı (RPC) türüne dayanır:
- RequestVotes RPC: Adaylar tarafından seçimler sırasında diğer düğümlerden oy istemek için kullanılır.
- AppendEntries RPC: Lider tarafından log girişlerini çoğaltmak ve takipçilere “kalp atışları” (heartbeat) göndermek için kullanılır. Kalp atışları, liderin varlığını düzenli olarak takipçilere bildirmesini sağlar.
Lider Seçimi
Tüm sunucular başlangıçta takipçi olarak başlar. Lider, takipçilere düzenli olarak kalp atışı mesajları göndererek yetkisini sürdürür. Her takipçinin, liderden kalp atışı beklediği bir zaman aşımı (genellikle 150 ila 300 ms arasında rastgele seçilir) vardır.
Eğer bir takipçi, zaman aşımı süresi içinde liderden bir kalp atışı almazsa, liderin başarısız olduğunu varsayar ve durumunu adaya değiştirir. Aday, mevcut terimini artırır, kendisine oy verir ve diğer tüm sunuculara RequestVote RPC’leri göndererek bir seçim başlatır.
Bir adayın seçimi kazanması için, kümedeki sunucuların çoğunluğundan aynı terim için oy alması gerekir. Çoğunluk kuralı, belirli bir terim için en fazla bir adayın seçimi kazanmasını sağlar. Her sunucu, belirli bir terimde en fazla bir adaya oy verir.
Seçimlerin üç olası sonucu vardır:
- Lider Olma: Aday, kümenin çoğunluğundan oy alırsa lider olur ve yetkisini tesis etmek ve yeni seçimleri önlemek için tüm diğer sunuculara kalp atışı mesajları göndermeye başlar.
- Takipçi Olma: Aday, yeni terimde başka bir sunucudan AppendEntries RPC’si (kalp atışı) alırsa, bu, başka bir liderin seçildiğini gösterir ve aday takipçi durumuna geri döner.
- Sonuçsuz Kalma: Oylama bir bölünmeyle sonuçlanırsa (hiçbir aday çoğunluk oyu alamazsa), aday aday durumunda kalır, bir süre uyur (yine rastgele bir zaman aşımı) ve yeni bir oylama turu başlatır. Rastgele seçim zaman aşımları, bölünmüş oyların nadir olmasını ve hızlı bir şekilde çözülmesini sağlar.
Go ile Lider Seçimi Örneği (Basitleştirilmiş)
Aşağıdaki Go kodu, Raft sunucu durumlarını, log girişini ve RPC mesajlarını tanımlar. Lider seçim sürecini simüle eden basitleştirilmiş bir RequestVote RPC işleyicisini de içerir.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// ServerState represents the possible states of a Raft server.
type ServerState int
const (
Follower ServerState = iota
Candidate
Leader
)
// LogEntry represents a single entry in the Raft log.
type LogEntry struct {
Term int // Term when this entry was created
Index int // Index of this entry in the log
Command string // Command to be applied
}
// RequestVoteArgs represents the arguments for a RequestVote RPC.
type RequestVoteArgs struct {
Term int // Candidate's term
CandidateID int // Candidate's ID
LastLogIndex int // Index of candidate's last log entry
LastLogTerm int // Term of candidate's last log entry
}
// RequestVoteReply represents the reply for a RequestVote RPC.
type RequestVoteReply struct {
Term int // Current term of the receiver
VoteGranted bool // Whether the candidate received vote
}
// AppendEntriesArgs represents the arguments for an AppendEntries RPC.
type AppendEntriesArgs struct {
Term int // Leader's term
LeaderID int // Leader's ID
PrevLogIndex int // Index of log entry immediately preceding new ones
PrevLogTerm int // Term of PrevLogIndex entry
Entries []LogEntry // Log entries to store (empty for heartbeat)
LeaderCommit int // Leader's commitIndex
}
// AppendEntriesReply represents the reply for an AppendEntries RPC.
type AppendEntriesReply struct {
Term int // Current term of the receiver
Success bool // True if follower contained entry matching PrevLogIndex and PrevLogTerm
}
// RaftServer represents a single server implementing the Raft algorithm.
type RaftServer struct {
ID int
State ServerState
CurrentTerm int
VotedFor int // CandidateID that received vote in current term
Log []LogEntry // Replicated log
CommitIndex int // Index of highest log entry known to be committed
LastApplied int // Index of highest log entry applied to state machine
// Volatile state for leaders
NextIndex []int // For each follower, index of the next log entry to send to that follower
MatchIndex []int // For each follower, index of the highest log entry replicated on follower
// For timeouts and communication
ElectionTimeout time.Duration
HeartbeatTimer *time.Timer
ElectionTimer *time.Timer
mu sync.Mutex // Mutex to protect server state
peers []*RaftServer // Other servers in the cluster (direct reference for simplicity)
}
// NewRaftServer creates a new Raft server.
func NewRaftServer(id int, peers []*RaftServer) *RaftServer {
r := &RaftServer{
ID: id,
State: Follower,
CurrentTerm: 0,
VotedFor: -1, // No vote yet
Log: []LogEntry{{Term: 0, Index: 0, Command: "init"}}, // Initial entry
CommitIndex: 0,
LastApplied: 0,
ElectionTimeout: time.Duration(150+rand.Intn(150)) * time.Millisecond, // 150-300ms
peers: peers,
}
r.ElectionTimer = time.AfterFunc(r.ElectionTimeout, func() { r.startElection() })
return r
}
// RequestVote processes a RequestVote RPC.
func (r *RaftServer) RequestVote(args RequestVoteArgs, reply *RequestVoteReply) {
r.mu.Lock()
defer r.mu.Unlock()
reply.Term = r.CurrentTerm
reply.VoteGranted = false
// If candidate's term is older, reject vote.
if args.Term < r.CurrentTerm {
fmt.Printf("Server %d: Candidate %d's term (%d) is older than mine (%d). Vote rejected.\n", r.ID, args.CandidateID, args.Term, r.CurrentTerm)
return
}
// If candidate's term is newer, update own term and become follower.
if args.Term > r.CurrentTerm {
r.CurrentTerm = args.Term
r.State = Follower
r.VotedFor = -1 // No vote yet in new term
r.resetElectionTimer()
fmt.Printf("Server %d: Candidate %d's term (%d) is newer than mine (%d). Became follower.\n", r.ID, args.CandidateID, args.Term, r.CurrentTerm)
}
// If haven't voted in this term (VotedFor is -1) or already voted for candidate,
// and candidate's log is at least as up-to-date as mine, grant vote.
if (r.VotedFor == -1 || r.VotedFor == args.CandidateID) && r.isLogUpToDate(args.LastLogIndex, args.LastLogTerm) {
r.VotedFor = args.CandidateID
reply.VoteGranted = true
r.resetElectionTimer() // Reset timer after voting
fmt.Printf("Server %d: Voted for candidate %d. (Term: %d)\n", r.ID, args.CandidateID, r.CurrentTerm)
} else {
fmt.Printf("Server %d: Did not vote for candidate %d. (VotedFor: %d, LogUpToDate: %t)\n", r.ID, args.CandidateID, r.VotedFor, r.isLogUpToDate(args.LastLogIndex, args.LastLogTerm))
}
}
// isLogUpToDate checks if the candidate's log is at least as up-to-date as the receiver's log.
func (r *RaftServer) isLogUpToDate(candidateLastLogIndex int, candidateLastLogTerm int) bool {
lastLogEntry := r.Log[len(r.Log)-1]
if candidateLastLogTerm > lastLogEntry.Term {
return true
}
if candidateLastLogTerm == lastLogEntry.Term && candidateLastLogIndex >= lastLogEntry.Index {
return true
}
return false
}
// startElection simulates a server starting a leader election.
func (r *RaftServer) startElection() {
r.mu.Lock()
r.State = Candidate
r.CurrentTerm++
r.VotedFor = r.ID // Vote for self
fmt.Printf("Server %d: Leader election started. New term: %d\n", r.ID, r.CurrentTerm)
r.resetElectionTimer() // Reset election timer
votesReceived := 1 // Our own vote
lastLogEntry := r.Log[len(r.Log)-1]
args := RequestVoteArgs{
Term: r.CurrentTerm,
CandidateID: r.ID,
LastLogIndex: lastLogEntry.Index,
LastLogTerm: lastLogEntry.Term,
}
r.mu.Unlock()
// Send vote requests to other servers
for _, peer := range r.peers {
if peer.ID == r.ID {
continue
}
go func(p *RaftServer) {
var reply RequestVoteReply
// Direct RPC call for simplicity, would be over network in real-world
p.RequestVote(args, &reply)
r.mu.Lock()
defer r.mu.Unlock()
if r.State != Candidate || r.CurrentTerm != args.Term {
// State changed or term changed, this vote is invalid.
return
}
if reply.Term > r.CurrentTerm {
// Discovered a newer term, become follower.
r.CurrentTerm = reply.Term
r.State = Follower
r.VotedFor = -1
r.resetElectionTimer()
fmt.Printf("Server %d: Discovered newer term (%d), became follower.\n", r.ID, reply.Term)
return
}
if reply.VoteGranted {
votesReceived++
fmt.Printf("Server %d: Received vote from candidate %d. Total votes: %d\n", r.ID, p.ID, votesReceived)
if votesReceived > len(r.peers)/2 {
// Received majority votes, become leader.
r.State = Leader
if r.HeartbeatTimer != nil {
r.HeartbeatTimer.Stop() // Stop any previous heartbeat timer
}
r.HeartbeatTimer = time.AfterFunc(50*time.Millisecond, func() { r.sendHeartbeats() }) // Start heartbeats
fmt.Printf("Server %d: Leader elected! (Term: %d)\n", r.ID, r.CurrentTerm)
r.resetElectionTimer() // Reset timer as leader
// Initialize nextIndex and matchIndex
r.NextIndex = make([]int, len(r.peers))
r.MatchIndex = make([]int, len(r.peers))
for i := range r.peers {
r.NextIndex[i] = len(r.Log)
r.MatchIndex[i] = 0
}
return
}
}
}(peer)
}
}
// resetElectionTimer resets the election timer.
func (r *RaftServer) resetElectionTimer() {
if r.ElectionTimer != nil {
r.ElectionTimer.Stop()
}
r.ElectionTimer = time.AfterFunc(r.ElectionTimeout, func() { r.startElection() })
}
// sendHeartbeats simulates the leader sending heartbeats to followers.
func (r *RaftServer) sendHeartbeats() {
r.mu.Lock()
defer r.mu.Unlock()
if r.State != Leader {
return
}
fmt.Printf("Leader %d: Sending heartbeats (Term: %d).\n", r.ID, r.CurrentTerm)
for i, peer := range r.peers {
if peer.ID == r.ID {
continue
}
go func(peerIndex int, p *RaftServer) {
var reply AppendEntriesReply
args := AppendEntriesArgs{
Term: r.CurrentTerm,
LeaderID: r.ID,
// Log entries are empty for heartbeats
PrevLogIndex: len(r.Log) - 1,
PrevLogTerm: r.Log[len(r.Log)-1].Term,
LeaderCommit: r.CommitIndex,
}
// If there are new entries to send
if len(r.Log) > r.NextIndex[peerIndex] {
args.Entries = r.Log[r.NextIndex[peerIndex]:]
args.PrevLogIndex = r.NextIndex[peerIndex] - 1
args.PrevLogTerm = r.Log[r.NextIndex[peerIndex]-1].Term
}
p.AppendEntries(args, &reply)
r.mu.Lock()
defer r.mu.Unlock()
if r.State != Leader || r.CurrentTerm != args.Term {
return // State changed or term changed
}
if reply.Term > r.CurrentTerm {
r.CurrentTerm = reply.Term
r.State = Follower
r.VotedFor = -1
r.resetElectionTimer()
fmt.Printf("Leader %d: Discovered newer term (%d), became follower.\n", r.ID, reply.Term)
return
}
if reply.Success {
// Update nextIndex and matchIndex for this follower
if len(args.Entries) > 0 {
r.NextIndex[peerIndex] = args.PrevLogIndex + len(args.Entries) + 1
r.MatchIndex[peerIndex] = r.NextIndex[peerIndex] - 1
}
// Check for commitment
r.checkCommit()
} else {
// Decrement nextIndex and retry AppendEntries
if r.NextIndex[peerIndex] > 1 {
r.NextIndex[peerIndex]--
fmt.Printf("Leader %d: AppendEntries failed for server %d. Decrementing nextIndex to %d.\n", r.ID, p.ID, r.NextIndex[peerIndex])
}
// Optionally, retry sending entries immediately
}
}(i, peer)
}
r.HeartbeatTimer = time.AfterFunc(50*time.Millisecond, func() { r.sendHeartbeats() }) // Regular heartbeats
}
// checkCommit attempts to advance the commitIndex based on replicated log entries.
func (r *RaftServer) checkCommit() {
N := r.CommitIndex
for i := len(r.Log) - 1; i > r.CommitIndex; i-- {
if r.Log[i].Term == r.CurrentTerm {
count := 1 // Count for self
for j := range r.peers {
if r.MatchIndex[j] >= i {
count++
}
}
if count > len(r.peers)/2 {
N = i
break
}
}
}
if N > r.CommitIndex {
r.CommitIndex = N
r.applyLogEntries()
}
}
// AppendEntries processes an AppendEntries RPC.
func (r *RaftServer) AppendEntries(args AppendEntriesArgs, reply *AppendEntriesReply) {
r.mu.Lock()
defer r.mu.Unlock()
reply.Term = r.CurrentTerm
reply.Success = false
if args.Term < r.CurrentTerm {
fmt.Printf("Server %d: Leader's term (%d) is older than mine (%d). AppendEntries rejected.\n", r.ID, args.Term, r.CurrentTerm)
return // Leader's term is older
}
if args.Term > r.CurrentTerm {
r.CurrentTerm = args.Term
r.State = Follower
r.VotedFor = -1
fmt.Printf("Server %d: Discovered newer term (%d) from leader, became follower.\n", r.ID, args.Term)
}
r.resetElectionTimer() // Received message from leader, reset timer
// Log consistency check
if args.PrevLogIndex >= len(r.Log) || r.Log[args.PrevLogIndex].Term != args.PrevLogTerm {
fmt.Printf("Server %d: Log inconsistency. PrevLogIndex: %d, PrevLogTerm: %d. My log: %v\n", r.ID, args.PrevLogIndex, args.PrevLogTerm, r.Log)
return
}
// Delete conflicting entries and append new ones
newEntriesStartIndex := args.PrevLogIndex + 1
if len(args.Entries) > 0 { // Only truncate if new entries exist to append
if len(r.Log) > newEntriesStartIndex {
r.Log = r.Log[:newEntriesStartIndex] // Truncate conflicting or subsequent entries
}
r.Log = append(r.Log, args.Entries...)
}
reply.Success = true
// Update leader's commit index
if args.LeaderCommit > r.CommitIndex {
r.CommitIndex = min(args.LeaderCommit, len(r.Log)-1)
r.applyLogEntries()
}
}
// applyLogEntries applies committed log entries to the state machine.
func (r *RaftServer) applyLogEntries() {
for r.LastApplied < r.CommitIndex {
r.LastApplied++
fmt.Printf("Server %d: Log entry applied: %s (Index: %d, Term: %d)\n", r.ID, r.Log[r.LastApplied].Command, r.Log[r.LastApplied].Index, r.Log[r.LastApplied].Term)
// Here would be the actual state machine application
}
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
func main() {
rand.Seed(time.Now().UnixNano())
// Create a cluster of 3 servers
servers := make([]*RaftServer, 3)
for i := 0; i < 3; i++ {
servers[i] = NewRaftServer(i, servers)
}
fmt.Println("Raft cluster started. Servers are in follower state.")
// Allow it to run for a while
time.Sleep(5 * time.Second)
// Simulate a client request to the leader
// Normally, the client would find the leader and send to it.
// Here, let's simply send to one server and expect the leader to process it.
// (In real Raft, the client would retry until it finds the leader)
fmt.Println("\nSending client request...")
leaderFound := false
for _, s := range servers {
s.mu.Lock()
if s.State == Leader {
fmt.Printf("Leader %d found. Sending client request.\n", s.ID)
newEntry := LogEntry{Term: s.CurrentTerm, Index: len(s.Log), Command: "SET x = 10"}
s.Log = append(s.Log, newEntry)
// Update nextIndex for all peers to include the new entry
for i := range s.peers {
if s.ID != s.peers[i].ID {
s.NextIndex[i] = len(s.Log) // Set to the index after the newly added entry
} else {
s.MatchIndex[i] = len(s.Log) - 1 // Leader's own log is committed
}
}
s.sendHeartbeats() // Trigger log replication
leaderFound = true
}
s.mu.Unlock()
if leaderFound {
break
}
}
if !leaderFound {
fmt.Println("Leader not found, try again or increase election timeout.")
}
time.Sleep(5 * time.Second)
fmt.Println("\nSimulation ended.")
}Bu kod, Raft’ın temel mekanizmalarını gösterir:
RaftServer struct:Bir Raft sunucusunun durumunu ve logunu tutar.RequestVoteArgs / RequestVoteReply:Seçim RPC’leri için veri yapıları.AppendEntriesArgs / AppendEntriesReply:Log çoğaltma ve kalp atışı RPC’leri için veri yapıları.startElection():Bir sunucunun adaya dönüşmesini, oy istemesini ve lider olmaya çalışmasını simüle eder.RequestVote():Diğer sunuculardan gelen oy isteklerini işler.sendHeartbeats():Liderin düzenli kalp atışları göndermesini ve log çoğaltmayı tetiklemesini simüle eder.AppendEntries():Takipçilerin liderden gelen log girişlerini işlemesini ve log tutarlılığını sağlamasını simüle eder.
Log Çoğaltma
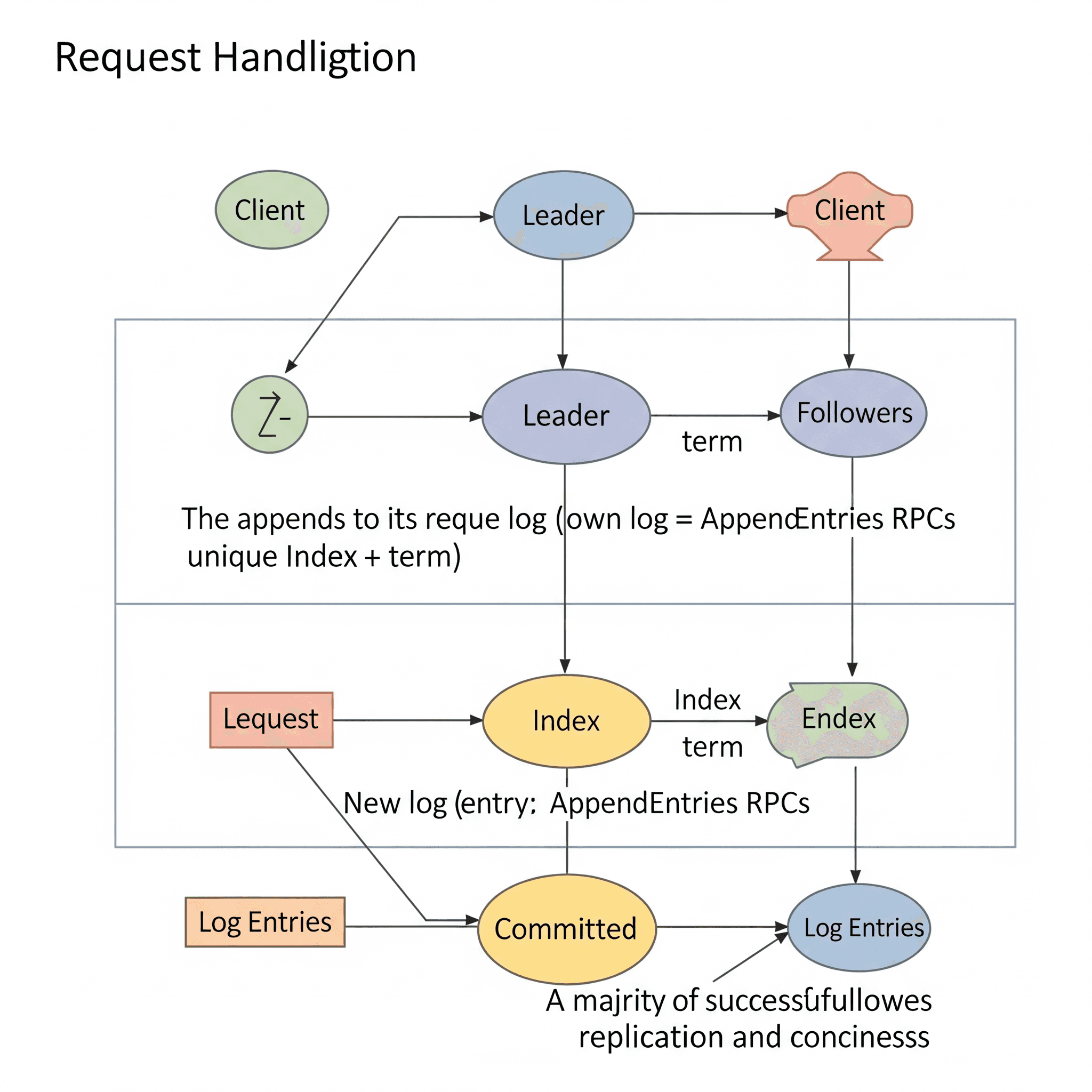
Bir lider seçildikten sonra, istemci isteklerini işlemeye başlar. Her veri değişikliği, Raft logunda yeni bir giriş olarak kaydedilir. Bu log girişi, lider tarafından kendi yerel loguna eklenir. Log girişi tipik olarak gerçekleştirilecek işlem hakkında bilgi içerir (örneğin, bir veritabanı yazma işlemi için anahtar-değer çiftleri).
Lider, log girişini kendi loguna ekledikten sonra, AppendEntries RPC’leri kullanarak bu log girişini takipçilere çoğaltır. Bu çoğaltma, tüm takipçilerin liderle aynı log girişleri dizisini almasını sağlar. Her takipçi, liderden aldığı log girişini kendi loguna ekler.
Bir log girişi, liderin çoğunluktaki takipçilerden log girişini çoğalttığına dair onay aldığında “taahhüt edilmiş” (committed) kabul edilir. Taahhüt edildikten sonra, lider ilgili işlemi kendi durum makinesine uygular ve istemciye yanıt verir. Lider, gelecekteki AppendEntries RPC’lerinde (kalp atışları dahil) taahhüt edilmiş girişleri diğer sunuculara bildirir, böylece takipçiler de bu girişleri kendi durum makinelerine uygulayabilir.
Raft, loglar arasında yüksek düzeyde tutarlılık sağlar ve bunu “Log Eşleştirme Özelliği” (Log Matching Property) ile garanti eder:
- Farklı loglardaki iki giriş aynı dizine ve terime sahipse, aynı komutu depolarlar.
- Farklı loglardaki iki giriş aynı dizine ve terime sahipse, loglar o girişe kadar tüm önceki girişlerde aynıdır.
Bu mekanizma sayesinde, bir lider iktidara geldiğinde log tutarlılığını sağlamak için özel bir eylemde bulunmasına gerek kalmaz. Normal çalışmaya başlar ve loglar, AppendEntries tutarlılık kontrolünün başarısızlıklarına yanıt olarak otomatik olarak yakınsar. Bir lider asla kendi logundaki girişleri üzerine yazmaz veya silmez.
Güvenlik Özellikleri
Raft, dağıtık sistemlerde tutarlılığı ve güvenilirliği sağlamak için bir dizi güvenlik özelliğini garanti eder:
- Seçim Güvenliği (Election Safety): Her terim için en fazla bir lider seçilebilir. Bu, her sunucunun yalnızca bir oy vermesi ve iki farklı adayın aynı terim içinde çoğunlukları asla biriktirememesiyle sağlanır.
- Lider Tamamlama (Leader Completeness): Yeni bir lider, önceki terimlerde taahhüt edilmiş tüm log girişlerini her zaman içerir. Bu, takipçilerin yalnızca kendi loglarından daha güncel olan bir adaya oy vermesiyle sağlanır.
- Log Eşleştirme (Log Matching): Yukarıda açıklandığı gibi, eğer iki logda aynı dizine ve terime sahip bir giriş varsa, o noktaya kadar loglar tamamen aynıdır.
- Durum Makinesi Güvenliği (State Machine Safety): Bir log girişi taahhüt edildikten sonra, değişmeyeceği garanti edilir. Bu, sistemin bütünlüğünü korur.
- Kalıcı Depolama (Persistent Storage): Her sunucu, mevcut terim, en son verilen oy ve log gibi kritik bilgileri kalıcı depolamada (disk veya flash gibi) saklar. Bu veriler, bir çökmeden sonra kurtarılabilmelidir.
- İstemci Etkileşimleri (Client Interactions): İstemciler yalnızca liderle etkileşime girer. Bir istemci başlangıçta herhangi bir sunucuya istek gönderebilir, ancak lider olmayan bir sunucu isteği reddeder ve en son lider hakkında bilgi döndürür. Lider bir istemci isteğini yürütürken çökerse, istemci istek başarılı olana kadar yeniden dener. Yinelenen komutların önlenmesi için, her komut benzersiz bir komut kimliğiyle eşleştirilir ve lider, yinelenen bir isteği algıladığında eski yanıtı yeniden yürütmeden gönderir.
Raft’ın Avantajları ve Sınırlamaları
Raft, dağıtık sistemlerde konsensus için güçlü bir çözüm sunarken, kendine özgü avantajları ve bazı sınırlamaları vardır:
Avantajlar
- Anlaşılabilirlik ve Basitlik: Raft’ın birincil tasarım hedefi, Paxos gibi diğer konsensus algoritmalarına kıyasla daha anlaşılır ve uygulanması daha kolay olmaktır. Bu, geliştiricilerin onu benimsemesini ve kullanmasını kolaylaştırır.
- Hata Toleransı: Raft, sunucu arızalarını etkili bir şekilde yönetebilir ve sistemin çalışır durumda kalmasını sağlayabilir. Kümenin çoğunluğu çalıştığı sürece sistem kullanılabilir kalır.
- Güçlü Tutarlılık: Raft, tüm düğümlerin aynı durumu korumasını garanti ederek güçlü tutarlılık sağlar. Modülerlik: Raft, konsensus problemini lider seçimi, log çoğaltma ve güvenlik gibi ayrı alt problemlere ayırır, bu da onu anlamayı ve uygulamayı kolaylaştırır.
Sınırlamalar
- Tek Lider Darboğazı: Lider, yoğun yük altında bir darboğaz haline gelebilir ve potansiyel olarak sistem performansını etkileyebilir. Tüm istemci istekleri liderden geçmek zorundadır.
- Bizans Hata Toleransı Yok: Raft, Bizans olmayan hataları varsayar. Bu, kötü niyetli saldırılar veya düğümlerin düzensiz davranmasına neden olan yazılım hataları gibi keyfi hataları ele almadığı anlamına gelir.
Gelişmiş Konular
Küme Üyeliği Değişiklikleri
Raft, küme yapılandırmasındaki değişiklikleri, yani düğüm ekleme veya kaldırma işlemlerini yönetme protokolünü tanımlar. Raft, genellikle tek sunuculu değişikliklere izin verir, yani aynı anda yalnızca bir sunucu eklenebilir veya silinebilir. Bu, özel AppendEntries girişleri kullanılarak iletişim kurulan küme yapılandırma değişiklikleri aracılığıyla gerçekleştirilir. ScyllaDB gibi bazı uygulamalar, Raft’ı kullanarak eşzamanlı düğüm ekleme veya kaldırma işlemlerine izin veren “işlemsel topoloji değişiklikleri” üzerinde çalışmaktadır.
Anlık Görüntüler (Snapshots)
Raft, log boyutunu sınırlamak için periyodik anlık görüntü mekanizmasını kullanır. Anlık görüntüler, belirli bir zamandaki sistemin durumunun bir görüntüsünü yakalar ve bu duruma ulaşmak için kullanılan tüm önceki log girişlerinin kaldırılmasına izin verir. Bu işlem otomatik olarak ve kullanıcı müdahalesi olmadan sunucularda gerçekleştirilir. Anlık görüntüler, tüm yapılandırmaları, sırlar motorlarını, kimlik doğrulama yöntemlerini, politikaları, belirteçleri ve depolanan sırları yedekler.
Pre-Vote ve Liderlik Transferi
Orijinal Raft algoritmasının uzantıları, kullanılabilirliği ve performansı artırmak için geliştirilmiştir:
- Pre-Vote: Bir üye kümeye yeniden katıldığında, zamanlamaya bağlı olarak zaten bir lider olmasına rağmen bir seçim tetikleyebilir. Bunu önlemek için, ön oylama önce diğer üyelerle kontrol eder. Gereksiz seçimi önlemek, kümenin kullanılabilirliğini artırır.
- Liderlik Transferi: Düzenli bir şekilde kapanan bir lider, liderliği açıkça başka bir üyeye devredebilir. Bu, bir zaman aşımı beklemekten daha hızlı olabilir. Ayrıca, başka bir üye daha iyi bir lider olduğunda (örneğin, daha hızlı bir makinede olduğunda) bir lider istifa edebilir.
Gerçek Dünya Uygulamaları
Raft algoritması, basitliği ve sağlamlığı nedeniyle birçok popüler dağıtık sistemde yaygın olarak benimsenmiştir:
- etcd: Kubernetes’in temel bir bileşenidir ve dağıtık sistemlerin çalışmaya devam etmesi için ihtiyaç duyduğu kritik bilgileri (yapılandırma verileri, durum verileri ve meta veriler) tutmak ve yönetmek için kullanılan açık kaynaklı bir dağıtık anahtar-değer deposudur. etcd, tüm düğümler arasında veri deposu tutarlılığını sağlamak için Raft konsensus algoritması üzerine kurulmuştur.
- Consul: Dağıtık sistemler için bir hizmet ağ çözümü olup, Raft algoritmasına dayalı dağıtık bir anahtar-değer deposu içerir. Hizmet kayıtlarının durumunu korumak için Raft’a güvenir.
- ScyllaDB: Yüksek verim ve öngörülebilir düşük gecikme süresi gerektiren veri yoğun uygulamalar için tasarlanmış bir NoSQL veritabanıdır. ScyllaDB, tutarlı işlemler gerçekleştirmek ve yönetilebilirliği ve tutarlılığı önemli ölçüde artırmak için Raft’ı uygulamaktadır.
- TiKV: Dağıtık bir veritabanı olan TiKV, hata toleransı için verileri birden çok kopya arasında senkronize etmek için Raft’ı kullanır.
Raft algoritması, dağıtık sistemlerde konsensus problemini çözmek için zarif ve pratik bir yaklaşım sunar. Paxos’un karmaşıklığına bir yanıt olarak tasarlanmış olması, onu geliştiriciler için daha erişilebilir ve anlaşılır hale getirmiştir. Lider seçimi, log çoğaltma ve güvenlik gibi temel bileşenlere ayrılmış yapısı, güçlü tutarlılık ve hata toleransı garantileriyle birleştiğinde, Raft’ı etcd, Consul ve ScyllaDB gibi modern dağıtık sistemlerin temel taşı haline getirmiştir. Raft, basitliği ve güvenilirliği dengeleyerek, günümüzün karmaşık ve dinamik bilişim ortamlarında sağlam ve ölçeklenebilir uygulamalar oluşturmak için vazgeçilmez bir araç olmaya devam etmektedir.
Kaynaklar
- https://en.wikipedia.org/wiki/Raft_(algorithm)
- https://web.stanford.edu/~ouster/cs190-winter22/lectures/raft/
- https://www.geeksforgeeks.org/paxos-vs-raft-algorithm-in-distributed-systems/
- https://www.mindbowser.com/raft-consensus-algorithm-explained/
- https://arorashu.github.io/posts/raft.html