Raft Algorithm: Simple and Reliable Consensus in Distributed Systems
May 2, 2025 • ☕️☕️☕️☕️ 19 min read • 🏷 computer, software, algorithm
Translated by author into: English
Raft Algorithm: Simple and Reliable Consensus in Distributed SystemsDistributed systems are the foundation of modern software architecture. But the simultaneous operation of multiple servers presents complex challenges, such as ensuring data consistency and system fault tolerance. At the heart of these challenges lies the problem of “consensus”: the ability of a group of servers to agree on a single value or action despite disruptions such as network outages or server failures. This article will take an in-depth look at the Raft algorithm, a simple and reliable algorithm designed to achieve consensus in distributed systems.
Why was Paxos Complex?
Before Raft, the de facto standard for distributed consensus was the Paxos algorithm. Defined by Leslie Lamport in the 1970s, Paxos offered a theoretically sound and fault-tolerant solution. However, the biggest criticism of Paxos was that it was extremely difficult to understand and correctly implement. Its complexity prevented developers from adopting and extending it, which triggered the search for alternatives.
Raft’s Fundamental Principles and Design Philosophy
Introduced by Diego Ongaro and John Ousterhout in 2013, Raft was designed as a more understandable alternative to Paxos. Raft’s primary goal was to increase understandability by separating logic and reducing the ways in which servers could be inconsistent.
Raft is based on the concept of “replicated state machines.” The basic idea is to ensure that separate servers agree on a specific “thing,” particularly a log. This log is a record of commands that change the system’s state. When all servers execute the same sequence of commands in the same order, they all reach the same state, and the system remains consistent.
Raft achieves this clarity by breaking the consensus problem into three independent subproblems:
- Leader Election: How to select a new leader if the current leader fails.
- Log Replication: How the leader accepts client requests and replicates them to other servers.
- Safety: Mechanisms that ensure the system never falls into an inconsistent state.
Raft addresses each of these sub-problems with clear and separate rules, adopting a “leader-based” approach unlike Paxos. Only one leader is elected in the cluster, and this leader is entirely responsible for managing log replication.
Raft Components and States
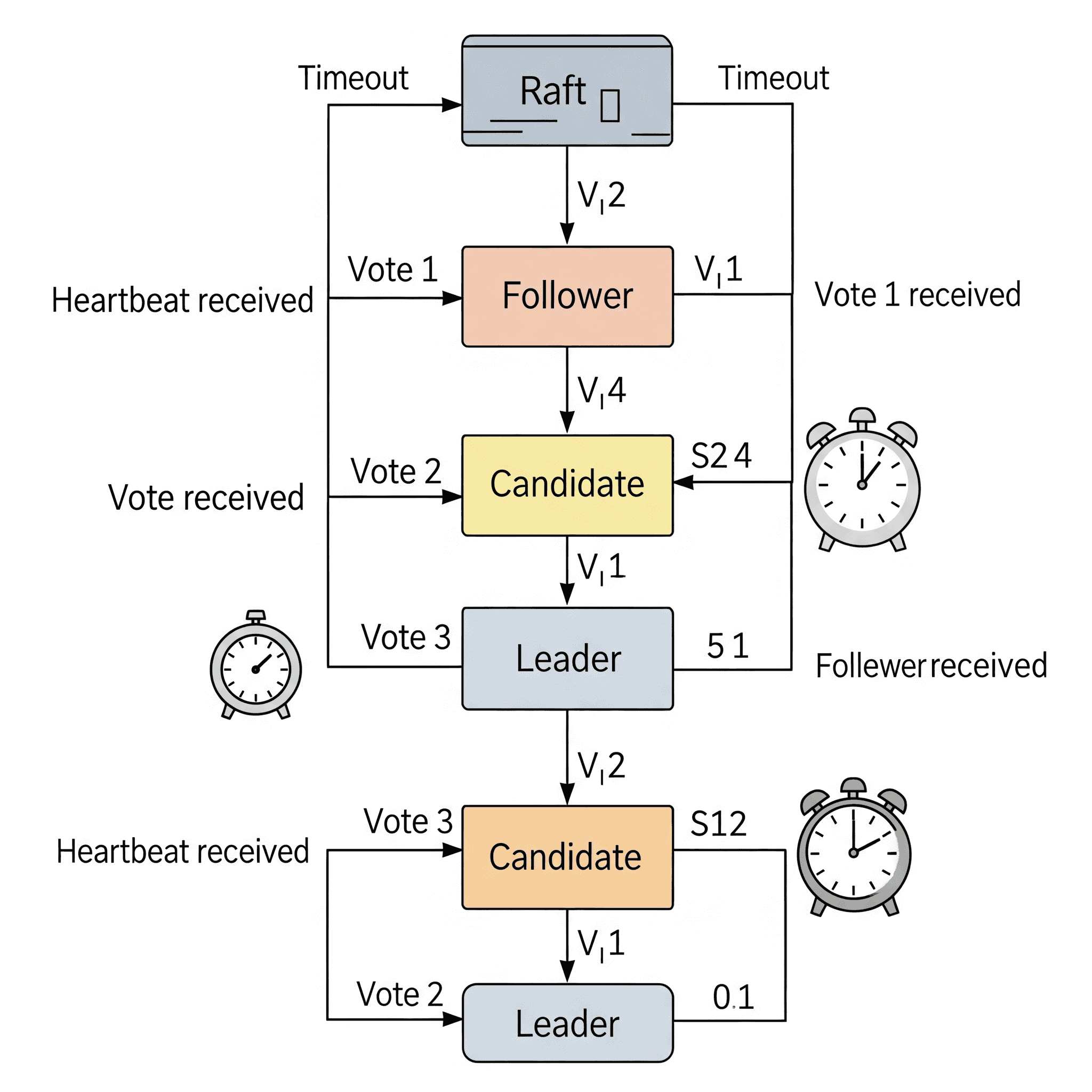
Each server in the Raft cluster is in one of three states at any given time:
- Leader: The central authority that accepts client requests, manages log entries, and replicates them to followers. In normal operation, there is exactly one leader in the cluster.
- Follower: Passive nodes that replicate the leader’s log entries and respond to requests from the leader.
- Candidate: Nodes that become candidates for leadership if the leader fails to respond within a certain period of time.
Terms
Raft divides time into logical time intervals numbered with sequential integers called “terms.” Each term begins with an election. Once a leader is elected, it remains in charge until the term ends or the leader fails. Term numbers help nodes synchronize their current information, resolve conflicts, and coordinate elections.
RPCs (Remote Procedure Calls)
Raft relies on two main types of Remote Procedure Calls (RPCs) for communication:
- RequestVotes RPC: Used by candidates to request votes from other nodes during elections.
- AppendEntries RPC: Used by the leader to replicate log entries and send “heartbeats” to followers. Heartbeats ensure that the leader regularly signals its presence to followers.
Leader Selection
All servers start as followers. The leader maintains its authority by regularly sending heartbeat messages to followers. Each follower has a timeout period (typically randomly selected between 150 and 300 ms) during which it expects to receive a heartbeat from the leader.
If a follower does not receive a heartbeat from the leader within the timeout period, it assumes the leader has failed and changes its status to candidate. The candidate increases its current term, votes for itself, and initiates an election by sending RequestVote RPCs to all other servers.
For a candidate to win the election, they must receive votes from the majority of servers in the cluster for the same term. The majority rule ensures that only one candidate can win the election for a given term. Each server votes for at most one candidate in a given term.
There are three possible outcomes for elections:
- Becoming the Leader: If a candidate receives votes from the majority of the cluster, they become the leader and begin sending heartbeat messages to all other servers to establish their authority and prevent new elections.
- Becoming a Follower: If a candidate receives an AppendEntries RPC (heartbeat) from another server in the new term, this indicates that another leader has been elected, and the candidate reverts to follower status.
- Remaining Undecided: If the vote results in a split (no candidate receives a majority of votes), the candidate remains in candidate status, sleeps for a period of time (again, a random timeout), and initiates a new round of voting. Random selection timeouts ensure that split votes are rare and resolved quickly.
Leader Election Example with Go (Simplified)
The following Go code defines Raft server states, log entries, and RPC messages. It also includes a simplified RequestVote RPC handler that simulates the leader election process.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// ServerState represents the possible states of a Raft server.
type ServerState int
const (
Follower ServerState = iota
Candidate
Leader
)
// LogEntry represents a single entry in the Raft log.
type LogEntry struct {
Term int // Term when this entry was created
Index int // Index of this entry in the log
Command string // Command to be applied
}
// RequestVoteArgs represents the arguments for a RequestVote RPC.
type RequestVoteArgs struct {
Term int // Candidate's term
CandidateID int // Candidate's ID
LastLogIndex int // Index of candidate's last log entry
LastLogTerm int // Term of candidate's last log entry
}
// RequestVoteReply represents the reply for a RequestVote RPC.
type RequestVoteReply struct {
Term int // Current term of the receiver
VoteGranted bool // Whether the candidate received vote
}
// AppendEntriesArgs represents the arguments for an AppendEntries RPC.
type AppendEntriesArgs struct {
Term int // Leader's term
LeaderID int // Leader's ID
PrevLogIndex int // Index of log entry immediately preceding new ones
PrevLogTerm int // Term of PrevLogIndex entry
Entries []LogEntry // Log entries to store (empty for heartbeat)
LeaderCommit int // Leader's commitIndex
}
// AppendEntriesReply represents the reply for an AppendEntries RPC.
type AppendEntriesReply struct {
Term int // Current term of the receiver
Success bool // True if follower contained entry matching PrevLogIndex and PrevLogTerm
}
// RaftServer represents a single server implementing the Raft algorithm.
type RaftServer struct {
ID int
State ServerState
CurrentTerm int
VotedFor int // CandidateID that received vote in current term
Log []LogEntry // Replicated log
CommitIndex int // Index of highest log entry known to be committed
LastApplied int // Index of highest log entry applied to state machine
// Volatile state for leaders
NextIndex []int // For each follower, index of the next log entry to send to that follower
MatchIndex []int // For each follower, index of the highest log entry replicated on follower
// For timeouts and communication
ElectionTimeout time.Duration
HeartbeatTimer *time.Timer
ElectionTimer *time.Timer
mu sync.Mutex // Mutex to protect server state
peers []*RaftServer // Other servers in the cluster (direct reference for simplicity)
}
// NewRaftServer creates a new Raft server.
func NewRaftServer(id int, peers []*RaftServer) *RaftServer {
r := &RaftServer{
ID: id,
State: Follower,
CurrentTerm: 0,
VotedFor: -1, // No vote yet
Log: []LogEntry{{Term: 0, Index: 0, Command: "init"}}, // Initial entry
CommitIndex: 0,
LastApplied: 0,
ElectionTimeout: time.Duration(150+rand.Intn(150)) * time.Millisecond, // 150-300ms
peers: peers,
}
r.ElectionTimer = time.AfterFunc(r.ElectionTimeout, func() { r.startElection() })
return r
}
// RequestVote processes a RequestVote RPC.
func (r *RaftServer) RequestVote(args RequestVoteArgs, reply *RequestVoteReply) {
r.mu.Lock()
defer r.mu.Unlock()
reply.Term = r.CurrentTerm
reply.VoteGranted = false
// If candidate's term is older, reject vote.
if args.Term < r.CurrentTerm {
fmt.Printf("Server %d: Candidate %d's term (%d) is older than mine (%d). Vote rejected.\n", r.ID, args.CandidateID, args.Term, r.CurrentTerm)
return
}
// If candidate's term is newer, update own term and become follower.
if args.Term > r.CurrentTerm {
r.CurrentTerm = args.Term
r.State = Follower
r.VotedFor = -1 // No vote yet in new term
r.resetElectionTimer()
fmt.Printf("Server %d: Candidate %d's term (%d) is newer than mine (%d). Became follower.\n", r.ID, args.CandidateID, args.Term, r.CurrentTerm)
}
// If haven't voted in this term (VotedFor is -1) or already voted for candidate,
// and candidate's log is at least as up-to-date as mine, grant vote.
if (r.VotedFor == -1 || r.VotedFor == args.CandidateID) && r.isLogUpToDate(args.LastLogIndex, args.LastLogTerm) {
r.VotedFor = args.CandidateID
reply.VoteGranted = true
r.resetElectionTimer() // Reset timer after voting
fmt.Printf("Server %d: Voted for candidate %d. (Term: %d)\n", r.ID, args.CandidateID, r.CurrentTerm)
} else {
fmt.Printf("Server %d: Did not vote for candidate %d. (VotedFor: %d, LogUpToDate: %t)\n", r.ID, args.CandidateID, r.VotedFor, r.isLogUpToDate(args.LastLogIndex, args.LastLogTerm))
}
}
// isLogUpToDate checks if the candidate's log is at least as up-to-date as the receiver's log.
func (r *RaftServer) isLogUpToDate(candidateLastLogIndex int, candidateLastLogTerm int) bool {
lastLogEntry := r.Log[len(r.Log)-1]
if candidateLastLogTerm > lastLogEntry.Term {
return true
}
if candidateLastLogTerm == lastLogEntry.Term && candidateLastLogIndex >= lastLogEntry.Index {
return true
}
return false
}
// startElection simulates a server starting a leader election.
func (r *RaftServer) startElection() {
r.mu.Lock()
r.State = Candidate
r.CurrentTerm++
r.VotedFor = r.ID // Vote for self
fmt.Printf("Server %d: Leader election started. New term: %d\n", r.ID, r.CurrentTerm)
r.resetElectionTimer() // Reset election timer
votesReceived := 1 // Our own vote
lastLogEntry := r.Log[len(r.Log)-1]
args := RequestVoteArgs{
Term: r.CurrentTerm,
CandidateID: r.ID,
LastLogIndex: lastLogEntry.Index,
LastLogTerm: lastLogEntry.Term,
}
r.mu.Unlock()
// Send vote requests to other servers
for _, peer := range r.peers {
if peer.ID == r.ID {
continue
}
go func(p *RaftServer) {
var reply RequestVoteReply
// Direct RPC call for simplicity, would be over network in real-world
p.RequestVote(args, &reply)
r.mu.Lock()
defer r.mu.Unlock()
if r.State != Candidate || r.CurrentTerm != args.Term {
// State changed or term changed, this vote is invalid.
return
}
if reply.Term > r.CurrentTerm {
// Discovered a newer term, become follower.
r.CurrentTerm = reply.Term
r.State = Follower
r.VotedFor = -1
r.resetElectionTimer()
fmt.Printf("Server %d: Discovered newer term (%d), became follower.\n", r.ID, reply.Term)
return
}
if reply.VoteGranted {
votesReceived++
fmt.Printf("Server %d: Received vote from candidate %d. Total votes: %d\n", r.ID, p.ID, votesReceived)
if votesReceived > len(r.peers)/2 {
// Received majority votes, become leader.
r.State = Leader
if r.HeartbeatTimer != nil {
r.HeartbeatTimer.Stop() // Stop any previous heartbeat timer
}
r.HeartbeatTimer = time.AfterFunc(50*time.Millisecond, func() { r.sendHeartbeats() }) // Start heartbeats
fmt.Printf("Server %d: Leader elected! (Term: %d)\n", r.ID, r.CurrentTerm)
r.resetElectionTimer() // Reset timer as leader
// Initialize nextIndex and matchIndex
r.NextIndex = make([]int, len(r.peers))
r.MatchIndex = make([]int, len(r.peers))
for i := range r.peers {
r.NextIndex[i] = len(r.Log)
r.MatchIndex[i] = 0
}
return
}
}
}(peer)
}
}
// resetElectionTimer resets the election timer.
func (r *RaftServer) resetElectionTimer() {
if r.ElectionTimer != nil {
r.ElectionTimer.Stop()
}
r.ElectionTimer = time.AfterFunc(r.ElectionTimeout, func() { r.startElection() })
}
// sendHeartbeats simulates the leader sending heartbeats to followers.
func (r *RaftServer) sendHeartbeats() {
r.mu.Lock()
defer r.mu.Unlock()
if r.State != Leader {
return
}
fmt.Printf("Leader %d: Sending heartbeats (Term: %d).\n", r.ID, r.CurrentTerm)
for i, peer := range r.peers {
if peer.ID == r.ID {
continue
}
go func(peerIndex int, p *RaftServer) {
var reply AppendEntriesReply
args := AppendEntriesArgs{
Term: r.CurrentTerm,
LeaderID: r.ID,
// Log entries are empty for heartbeats
PrevLogIndex: len(r.Log) - 1,
PrevLogTerm: r.Log[len(r.Log)-1].Term,
LeaderCommit: r.CommitIndex,
}
// If there are new entries to send
if len(r.Log) > r.NextIndex[peerIndex] {
args.Entries = r.Log[r.NextIndex[peerIndex]:]
args.PrevLogIndex = r.NextIndex[peerIndex] - 1
args.PrevLogTerm = r.Log[r.NextIndex[peerIndex]-1].Term
}
p.AppendEntries(args, &reply)
r.mu.Lock()
defer r.mu.Unlock()
if r.State != Leader || r.CurrentTerm != args.Term {
return // State changed or term changed
}
if reply.Term > r.CurrentTerm {
r.CurrentTerm = reply.Term
r.State = Follower
r.VotedFor = -1
r.resetElectionTimer()
fmt.Printf("Leader %d: Discovered newer term (%d), became follower.\n", r.ID, reply.Term)
return
}
if reply.Success {
// Update nextIndex and matchIndex for this follower
if len(args.Entries) > 0 {
r.NextIndex[peerIndex] = args.PrevLogIndex + len(args.Entries) + 1
r.MatchIndex[peerIndex] = r.NextIndex[peerIndex] - 1
}
// Check for commitment
r.checkCommit()
} else {
// Decrement nextIndex and retry AppendEntries
if r.NextIndex[peerIndex] > 1 {
r.NextIndex[peerIndex]--
fmt.Printf("Leader %d: AppendEntries failed for server %d. Decrementing nextIndex to %d.\n", r.ID, p.ID, r.NextIndex[peerIndex])
}
// Optionally, retry sending entries immediately
}
}(i, peer)
}
r.HeartbeatTimer = time.AfterFunc(50*time.Millisecond, func() { r.sendHeartbeats() }) // Regular heartbeats
}
// checkCommit attempts to advance the commitIndex based on replicated log entries.
func (r *RaftServer) checkCommit() {
N := r.CommitIndex
for i := len(r.Log) - 1; i > r.CommitIndex; i-- {
if r.Log[i].Term == r.CurrentTerm {
count := 1 // Count for self
for j := range r.peers {
if r.MatchIndex[j] >= i {
count++
}
}
if count > len(r.peers)/2 {
N = i
break
}
}
}
if N > r.CommitIndex {
r.CommitIndex = N
r.applyLogEntries()
}
}
// AppendEntries processes an AppendEntries RPC.
func (r *RaftServer) AppendEntries(args AppendEntriesArgs, reply *AppendEntriesReply) {
r.mu.Lock()
defer r.mu.Unlock()
reply.Term = r.CurrentTerm
reply.Success = false
if args.Term < r.CurrentTerm {
fmt.Printf("Server %d: Leader's term (%d) is older than mine (%d). AppendEntries rejected.\n", r.ID, args.Term, r.CurrentTerm)
return // Leader's term is older
}
if args.Term > r.CurrentTerm {
r.CurrentTerm = args.Term
r.State = Follower
r.VotedFor = -1
fmt.Printf("Server %d: Discovered newer term (%d) from leader, became follower.\n", r.ID, args.Term)
}
r.resetElectionTimer() // Received message from leader, reset timer
// Log consistency check
if args.PrevLogIndex >= len(r.Log) || r.Log[args.PrevLogIndex].Term != args.PrevLogTerm {
fmt.Printf("Server %d: Log inconsistency. PrevLogIndex: %d, PrevLogTerm: %d. My log: %v\n", r.ID, args.PrevLogIndex, args.PrevLogTerm, r.Log)
return
}
// Delete conflicting entries and append new ones
newEntriesStartIndex := args.PrevLogIndex + 1
if len(args.Entries) > 0 { // Only truncate if new entries exist to append
if len(r.Log) > newEntriesStartIndex {
r.Log = r.Log[:newEntriesStartIndex] // Truncate conflicting or subsequent entries
}
r.Log = append(r.Log, args.Entries...)
}
reply.Success = true
// Update leader's commit index
if args.LeaderCommit > r.CommitIndex {
r.CommitIndex = min(args.LeaderCommit, len(r.Log)-1)
r.applyLogEntries()
}
}
// applyLogEntries applies committed log entries to the state machine.
func (r *RaftServer) applyLogEntries() {
for r.LastApplied < r.CommitIndex {
r.LastApplied++
fmt.Printf("Server %d: Log entry applied: %s (Index: %d, Term: %d)\n", r.ID, r.Log[r.LastApplied].Command, r.Log[r.LastApplied].Index, r.Log[r.LastApplied].Term)
// Here would be the actual state machine application
}
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
func main() {
rand.Seed(time.Now().UnixNano())
// Create a cluster of 3 servers
servers := make([]*RaftServer, 3)
for i := 0; i < 3; i++ {
servers[i] = NewRaftServer(i, servers)
}
fmt.Println("Raft cluster started. Servers are in follower state.")
// Allow it to run for a while
time.Sleep(5 * time.Second)
// Simulate a client request to the leader
// Normally, the client would find the leader and send to it.
// Here, let's simply send to one server and expect the leader to process it.
// (In real Raft, the client would retry until it finds the leader)
fmt.Println("\nSending client request...")
leaderFound := false
for _, s := range servers {
s.mu.Lock()
if s.State == Leader {
fmt.Printf("Leader %d found. Sending client request.\n", s.ID)
newEntry := LogEntry{Term: s.CurrentTerm, Index: len(s.Log), Command: "SET x = 10"}
s.Log = append(s.Log, newEntry)
// Update nextIndex for all peers to include the new entry
for i := range s.peers {
if s.ID != s.peers[i].ID {
s.NextIndex[i] = len(s.Log) // Set to the index after the newly added entry
} else {
s.MatchIndex[i] = len(s.Log) - 1 // Leader's own log is committed
}
}
s.sendHeartbeats() // Trigger log replication
leaderFound = true
}
s.mu.Unlock()
if leaderFound {
break
}
}
if !leaderFound {
fmt.Println("Leader not found, try again or increase election timeout.")
}
time.Sleep(5 * time.Second)
fmt.Println("\nSimulation ended.")
}Leader Election Example with Go (Simplified)
The following Go code defines Raft server states, log entries, and RPC messages. It also includes a simplified RequestVote RPC handler that simulates the leader election process. This code demonstrates the basic mechanisms of Raft:
RaftServer struct:Holds the state and log of a Raft server.RequestVoteArgs / RequestVoteReply:Data structures for election RPCs.AppendEntriesArgs / AppendEntriesReply:Data structures for log replication and heartbeat RPCs.startElection():Simulates a server becoming a candidate, requesting votes, and attempting to become leader.RequestVote():Processes vote requests from other servers.sendHeartbeats():Simulates the leader sending regular heartbeats and triggering log replication.AppendEntries():Simulates followers processing log entries from the leader and ensuring log consistency.
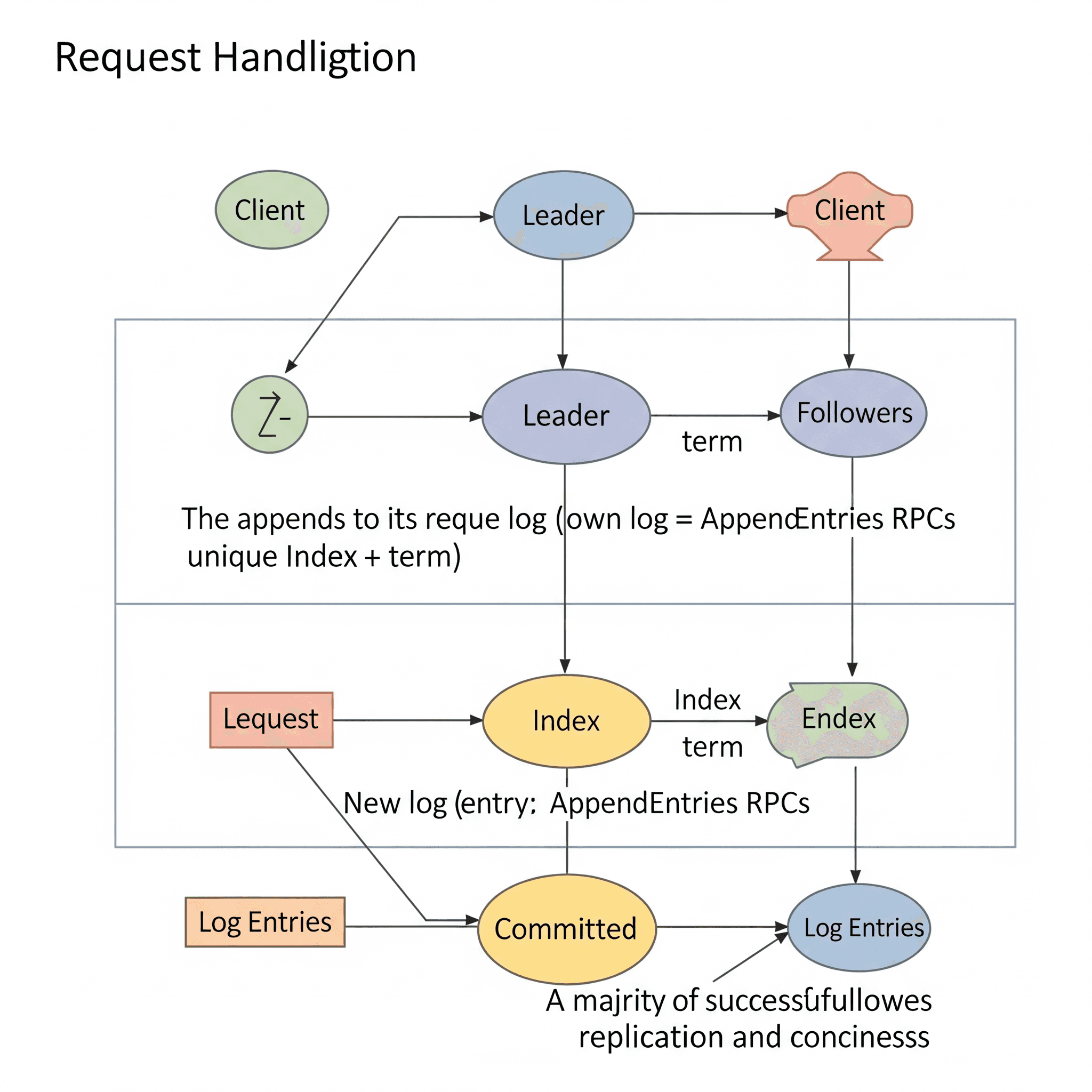
Log Replication
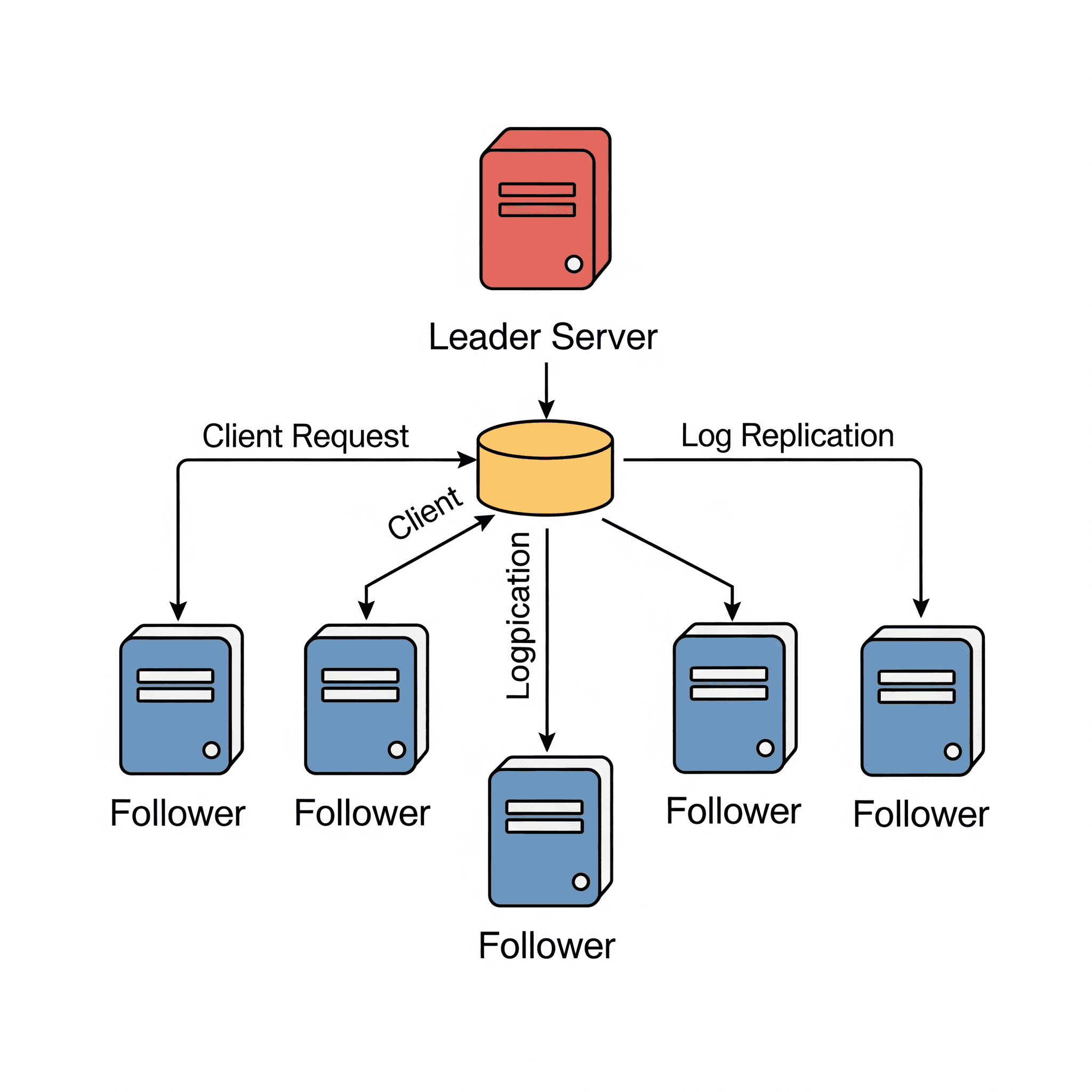
Once a leader is elected, it begins processing client requests. Each data change is recorded as a new entry in the Raft log. This log entry is appended to the leader’s local log. The log entry typically contains information about the operation to be performed (e.g., key-value pairs for a database write operation).
After the leader adds the log entry to its own log, it replicates this log entry to the followers using AppendEntries RPCs. This replication ensures that all followers receive the same sequence of log entries as the leader. Each follower adds the log entry it receives from the leader to its own log.
A log entry is considered “committed” when the leader receives confirmation from the majority of followers that they have replicated the log entry. Once committed, the leader applies the relevant transaction to its state machine and responds to the client. The leader notifies other servers of committed entries in future AppendEntries RPCs (including heartbeats), so that followers can also apply these entries to their state machines.
Raft ensures a high level of consistency between logs and guarantees this with the “Log Matching Property”:
- If two entries in different logs have the same index and term, they store the same command.
- If two entries in different logs have the same index and term, the logs are the same for all previous entries up to that entry.
Thanks to this mechanism, when a leader comes to power, there is no need for them to take any special action to ensure log consistency. They simply start normal operation, and the logs automatically converge in response to failures in the AppendEntries consistency check. A leader never overwrites or deletes entries in their own log.
Security Features
Raft guarantees a set of security features to ensure consistency and reliability in distributed systems:
- Election Safety: At most one leader can be elected per term. This is ensured by each server casting only one vote and no two different candidates ever accumulating a majority within the same term.
- Leader Completeness: A new leader always includes all log entries committed in previous terms. This is ensured by followers only voting for a candidate whose log is more up-to-date than their own.
- Log Matching: As explained above, if two logs have an entry with the same index and term, the logs are identical up to that point.
- State Machine Safety: Once a log entry is committed, it is guaranteed not to change. This preserves the integrity of the system.
- Persistent Storage: Each server stores critical information such as the current term, the last vote cast, and the log in persistent storage (such as a disk or flash). This data must be recoverable after a crash.
- Client Interactions: Clients only interact with the leader. A client can initially send a request to any server, but a non-leader server will reject the request and return information about the current leader. If the leader crashes while executing a client request, the client retries until the request is successful. To prevent repeated commands, each command is paired with a unique command ID, and when the leader detects a repeated request, it sends the old response without re-executing it.
Advantages and Limitations of Raft
While Raft offers a robust solution for consensus in distributed systems, it has its own unique advantages and some limitations:
Advantages
- Understandability and Simplicity: Raft’s primary design goal is to be more understandable and easier to implement compared to other consensus algorithms like Paxos. This makes it easier for developers to adopt and use it.
- Fault Tolerance: Raft can effectively manage server failures and keep the system up and running. As long as the majority of the cluster is operational, the system remains available.
- Strong Consistency: Raft ensures strong consistency by guaranteeing that all nodes maintain the same state. Modularity: Raft breaks down the consensus problem into separate subproblems such as leader election, log replication, and security, making it easier to understand and implement.
Limitations
- Single Leader Bottleneck: The leader can become a bottleneck under heavy load and potentially impact system performance. All client requests must go through the leader.
- No Byzantine Fault Tolerance: Raft assumes non-Byzantine faults. This means it does not handle arbitrary faults such as malicious attacks or software bugs that cause nodes to behave erratically.
Advanced Topics
Cluster Membership Changes
Raft defines the protocol for managing changes to the cluster configuration, i.e., adding or removing nodes. Raft typically allows single-server changes, meaning that only one server can be added or removed at a time. This is achieved through cluster configuration changes communicated using special AppendEntries entries. Some applications, such as ScyllaDB, are working on “transactional topology changes” that allow concurrent node addition or removal using Raft.
Snapshots
Raft uses a periodic snapshot mechanism to limit log size. Snapshots capture a snapshot of the system’s state at a specific point in time and allow all previous log entries used to reach that state to be removed. This process is performed automatically on servers without user intervention. Snapshots back up all configurations, secret engines, authentication methods, policies, tokens, and stored secrets.
Pre-Vote and Leadership Transfer
Extensions to the original Raft algorithm have been developed to improve availability and performance:
- Pre-Vote: When a member rejoins the cluster, it may trigger an election even though there is already a leader, depending on the timing. To prevent this, the pre-vote checks with other members first. Avoiding unnecessary elections improves the cluster’s availability.
- Leadership Transfer: A leader that is shutting down regularly can explicitly transfer leadership to another member. This can be faster than waiting for a timeout. Additionally, a leader may resign when another member is a better leader (e.g., when they are on a faster machine).
Real-World Applications
The Raft algorithm has been widely adopted in many popular distributed systems due to its simplicity and robustness:
- etcd: A core component of Kubernetes, etcd is an open-source distributed key-value store used to hold and manage the critical information (configuration data, state data, and metadata) that distributed systems need to continue operating. etcd is built on the Raft consensus algorithm to ensure data store consistency across all nodes.
- Consul: A service mesh solution for distributed systems, it includes a distributed key-value store based on the Raft algorithm. It relies on Raft to maintain the state of service registrations.
- ScyllaDB: A NoSQL database designed for data-intensive applications requiring high throughput and predictable low latency. ScyllaDB implements Raft to perform consistent transactions and significantly increase manageability and consistency.
- TiKV: TiKV, a distributed database, uses Raft to synchronize data across multiple copies for fault tolerance.
The Raft algorithm offers an elegant and practical approach to solving the consensus problem in distributed systems. Designed as a response to the complexity of Paxos, it has made it more accessible and understandable for developers. Its structure, divided into core components such as leader election, log replication, and safety, combined with strong consistency and fault tolerance guarantees, has made Raft the cornerstone of modern distributed systems like etcd, Consul, and ScyllaDB. By balancing simplicity and reliability, Raft remains an indispensable tool for building robust and scalable applications in today’s complex and dynamic computing environments.
Resources
- https://en.wikipedia.org/wiki/Raft_(algorithm)
- https://web.stanford.edu/~ouster/cs190-winter22/lectures/raft/
- https://www.geeksforgeeks.org/paxos-vs-raft-algorithm-in-distributed-systems/
- https://www.mindbowser.com/raft-consensus-algorithm-explained/
- https://arorashu.github.io/posts/raft.html